인과추론의 데이터과학. (2021, Oct 11). [Session 11-1] 인과추론과 예측 방법론의 차이 [Video]. YouTube.
인과추론의 데이터과학. (2021, Oct 11). [Session 11-2] 실증연구에서의 빅데이터와 머신러닝의 역할 [Video]. YouTube.
인과추론의 데이터과학. (2021, Oct 18). [Session 11-3] 인과추론에서의 머신러닝의 활용 [Video]. YouTube.
인과추론의 데이터과학. (2021, Oct 18). [Session 11-4] 인과추론 기반의 예측 모델링 평가 [Video]. YouTube.[Video]. YouTube.
Session 11-1
Moneyball Lessons learned
- 팀의 성적 향상이라는 공통된 목적 안에서 다른 세부적인 관점
- Baseball Scout의 목표: 선수를 영입, 그들의 방식으로 득점을 끌어올리는 목적
- 좋은 스윙, 타구등 작은 습관을 기준으로 선수 영입
- 장기적으로 성장 가능성 + 지속적으로 코칭을 통한 발전 → 경험적으로 생성된 인과적 사고방식
- Data Scientist의 목표: 득점을 극대화할 수 있는 선수 영입
- 출루율, 득점률 등 데이터를 기반으로 한 선수 영입
- Baseball Scout의 목표: 선수를 영입, 그들의 방식으로 득점을 끌어올리는 목적
- 중요한 교훈: The right tool for the right question
Data Science / Analytics의 framework 목적
- Input → Mechanism Theory Algorithm → Output
- Intervention-oriented research (Input) → Causal inference model
- intput을 조정하고 처리하는 것에 목적이 있는 경우
- 어떤 변수가 output을 잘 예측하는 경우, 인과적인 관계를 실험해 볼 수도 있음
- Solution-oriented research (Output) → Predictive model
- target과 유사한 output을 얻는 것에 목적이 있는 경우
Example 1:
- Setting
- Intput (Safety Inspections)
- Output (Urban Safety)
- Intput → 어떤 요인(ex. 건물, 식당)이 식품 안전에 위협이 되는지 인과추론 실행
- Output → 도시 안전 예측이 목적이라면, Predictive model 활용
Example 2:
- Setting
- Intput (Relationships in social networks)
- Mechanism Theory Algorithm(Homophily, Peer influence)
- Output (Sales, word-of-mouth)
- Intervention: social network상에서 influence marketing
- node끼리 서로 영향을 준다고 알려진 경우, 영향력 있는 node에 마케팅을 함으로써 구전효과를 빨리 일으키도록 유도할 수 있음
- Correlation: 개별적으로 서로 영향이 없더라도, 사회적 유대는 좋은 예측 도구가 될 수 있음
Example 3:
- Data: 전자 의료 기록
- 목표
- 뇌졸중 확률을 예측 → Predictive model
- statin의 약물 처방이 뇌졸중을 낮출 수 있는지 인과추론 가능 → Causal inference
Causal inference VS Predictive model
- Difference
- To explain / To predict
- Causation / Association (Correlation)
- Bias / Variance
- Retrospective (in-sample) / Prospective (out-of-sample)
- Bias / Variance
- MSE Decomposition
$$ \begin{align*} E[(Y-\hat{f}(x))]^2 &= Var[\epsilon] + \{E[\hat{f}(x)]-f(x)\}^2\\ + E[(\hat{f}(x) - E[\hat{f}(x)])^2] \\ &= Var[\epsilon] + Bias^2 + Var[\hat{f}(x)] \end{align*} $$ - Predictive model: minimize MSE (combination of bias and variance)
- Causal inference: minimize bias
- 실제로는 bias를 계산할 수가 없음 (이론적으로만 MSE decomposition이 가능)
- MSE Decomposition
- 목적에 따른 방법론 분류
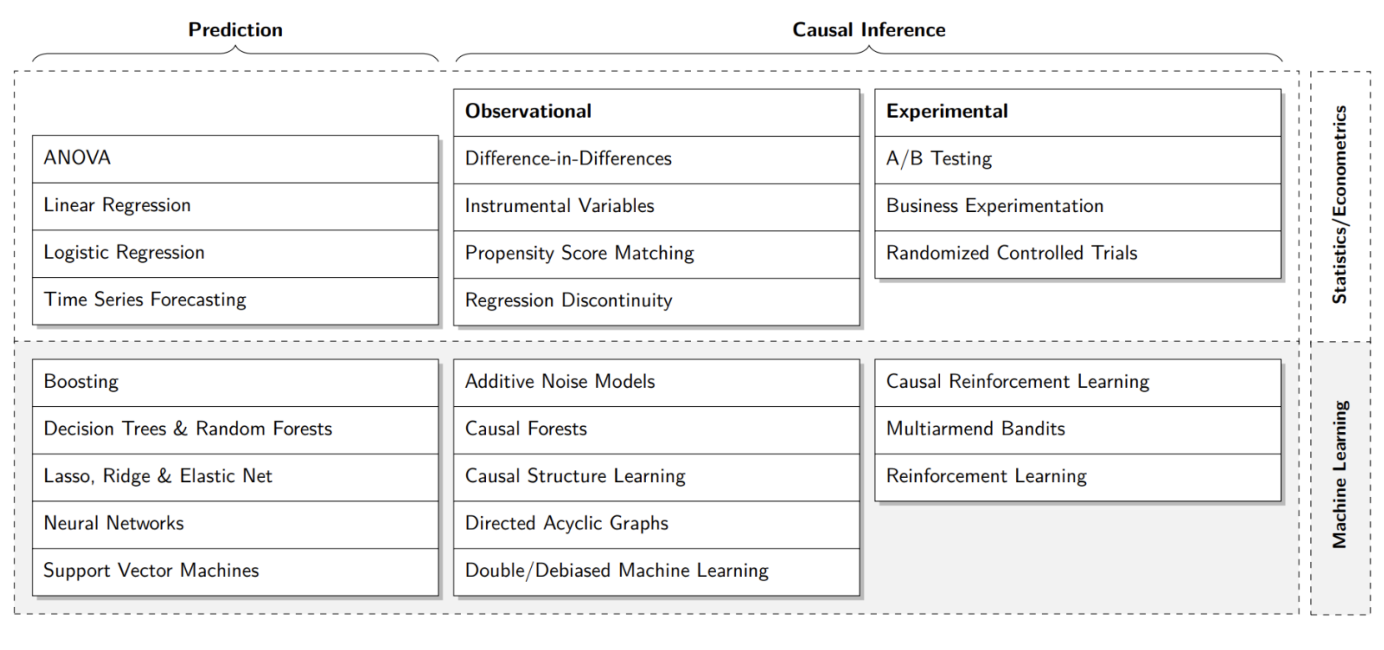
Session 11-2
Big data, ML in Causal Inference
- Computational Social Science ≠ Computer Science + Social data
- social scientist : causal inference를 추구하는 사람
- computer scientist : prediction을 추구하는 사람
- Big data가 근본적인 인과 추론 문제를 해결할 수 있나요?
- 아니요 → 데이터를 활용한 potential outcome이기 때문에, counterfactual은 알 수가 없어요.
- Large N (sample 수) → 중요한 결과를 얻는 것에는 도움을 주지만, unbiased estimate을 얻는데는 도움 안 됨
- Large P (variable 수) → 데이터와 변수가 많을 수록, control / conditioning이 가능함 ⇒ 하지만, 결과 변수에 영향을 미치는 모든 변수를 얻을 수 있을지는 미지수
- Research design은 빅 데이터 시대에도 중요하다
연구 방법론의 3가지 딜레마
- 딜레마
- Generalizability: 전체 모수에 대해 일반화가 가능한지
- formal theory: 타당한 이론 정립
- sample surveys: 랜덤 샘플링이 전제가 되어야함
- Control: internal validity; rigor → 얼마나 선택 편향을 배제함으로써 인과추론을 깔끔하게 할 수 있는지
- laboratory experiments
- Realism: external validity; relevance →실제 현실에 적용 가능한지
- field experiment, field studies : 실제 현장에서 세팅되어야 함
- Generalizability: 전체 모수에 대해 일반화가 가능한지
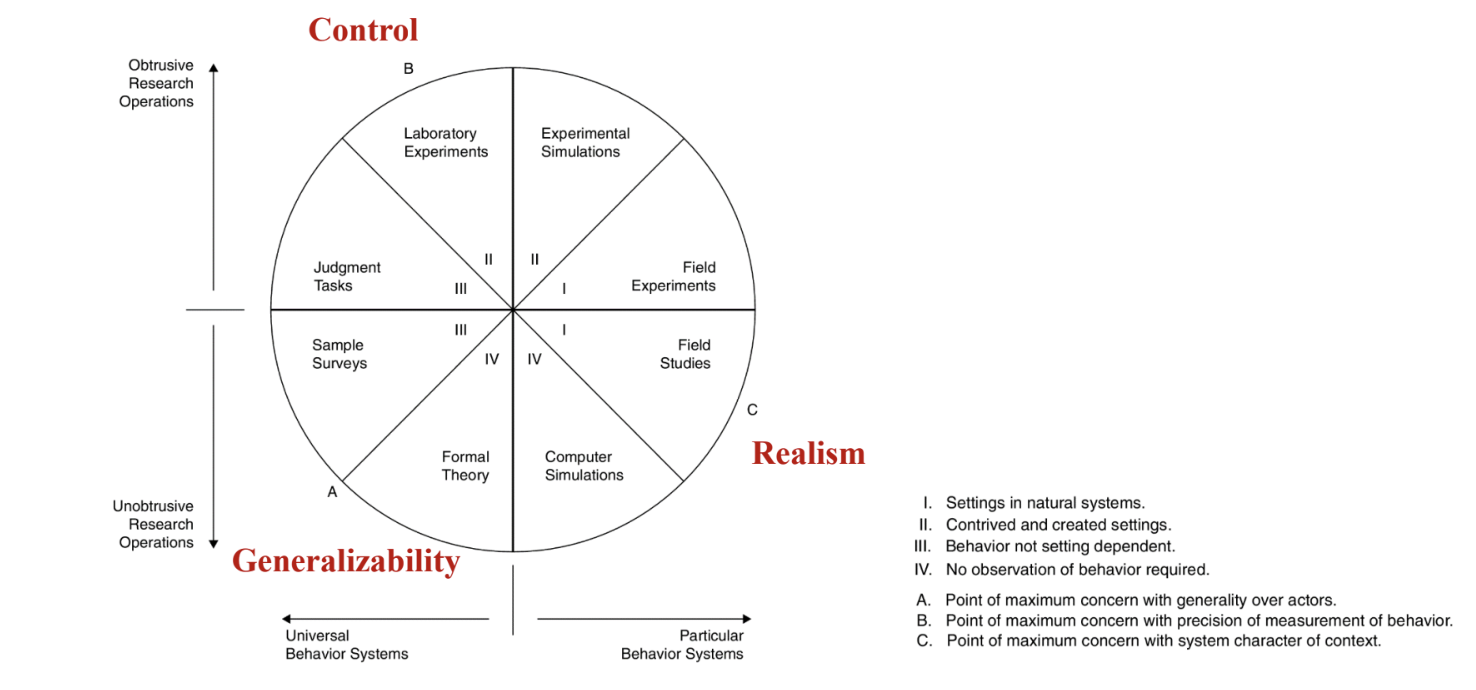
- Reconciling Internal and External Validities
- randomized field experiment on Facebook → Control, Realism
- sample of 1.3 million users → Generalizability
- Uncovering the Underlying Mechanisms
- 빅 데이터의 힘은 세밀한 데이터를 확보할 수 있는 것
- 인과 효과를 robust하게 추정 가능
- 조건에 따라 다른 heterogeneity(이질성)를 분석 가능
- Underlying Mechanisms을 밝힐 수 있음
- 빅 데이터의 힘은 세밀한 데이터를 확보할 수 있는 것
- 과거에 분석하기 어려웠던 unstructured data를 large scale로 분석 가능 → Empirical Research의 폭을 확장함
- ex. 성격 연구: 과거에는 설문 조사, 인터뷰를 했을 것 (대규모 분석의 한계) → 현재는 텍스트를 기반으로 NLP를 활용한 예측 가능
Session 11-3
New data for Causal Inference
- 빅데이터와 ML이 새로운 인과추론을 할 수 있게함
- ML, DL은 5V 중에서 Volume, Variety와 관련이 있음
→ large scale 분석 가능, 인과 추론의 범위가 확장됨 - Example
- Earning Conference Calls에서 사용하는 단어 기반, 회사 문화 분류
- 이미지의 복잡성에 따라 소비자의 참여도가 어떻게 달라지는지 분석
- App Store에서 Copycat App을 찾아내는 알고리즘 → Copycat App이 모바일 생태계에 미치는 영향 분석 가능
인과추론의 보조 수단으로 ML 모델 응용
- 도구 변수: 1번째 stage는 도구 변수로 원인변수를 예측하는 것 → ML을 활용
- ML을 활용하여 차원 축소를 통해 차원의 저주를 해결 가능
- 차원의 저주(Curse of dimensionality): 추정하는 변수가 관측에 비해 너무 많은 경우, 통계적 추정이 효율적이지 않음
- ex. double selection procedure ⇒ 선택 편향을 통제 + 차원의 저주 방지
- 결과 변수 예측에 도움이 되는 변수를 select
- 원인 변수 예측에 도움이 되는 변수를 select
Heterogeneous Causal Effects
- Heterogeneous: 이질적인
- ML이 인과추론에서 가장 많이 활용되고 있는 분야
- Causal decision making에 중요한 부분
- ex. Decision Tree, RF을 활용
- 기존: loss function → MSE 최소화
- 신규: loss function → Causal effect 극대화
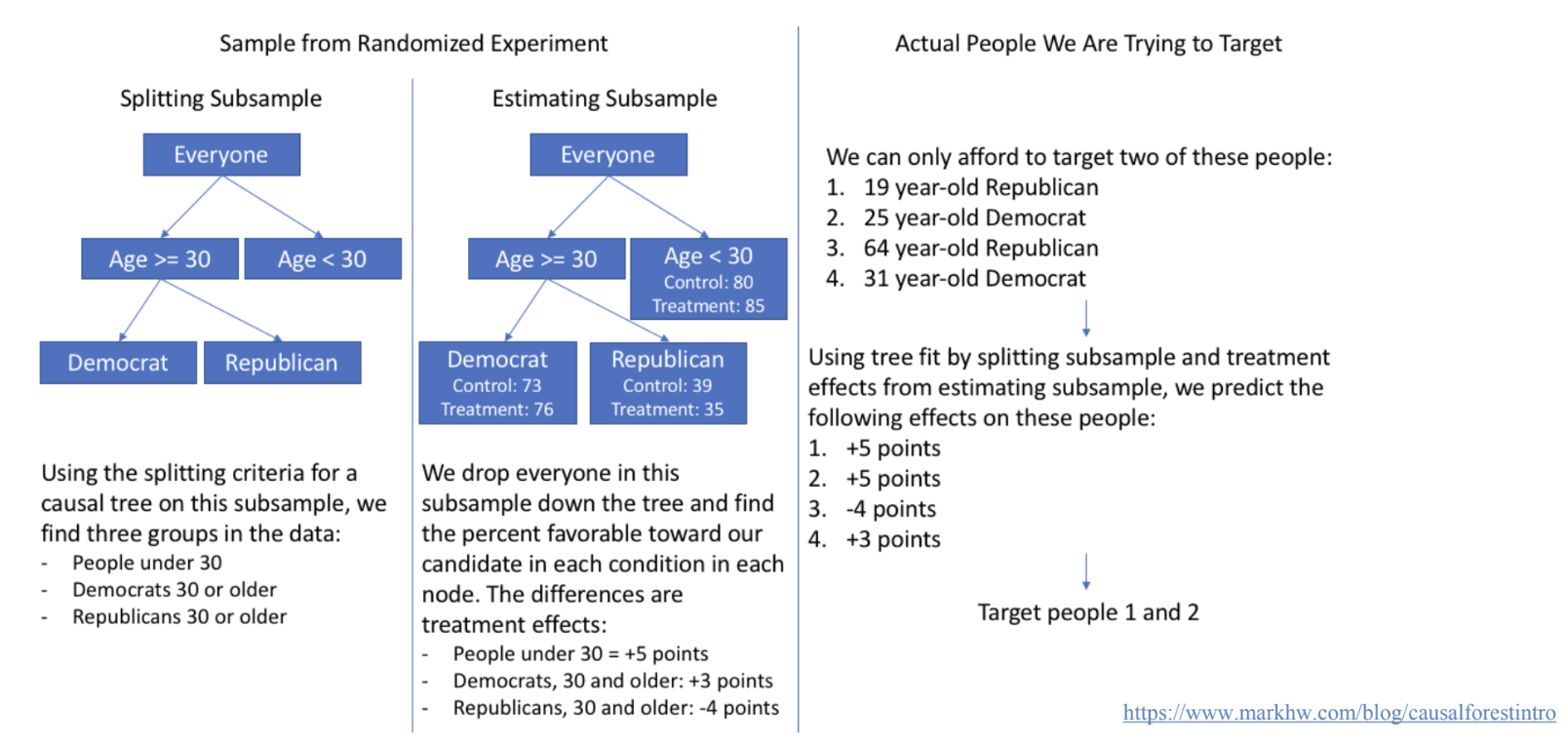
Synthetic Control (Pseudo-Counterfactual)
- Potential outcomes framework → 비교가능한 control group으로 Counterfactual을 추정
- Ceteris Paribus
- Synthetic control: control group을 잘 종합하는 것으로 Counterfactual을 추정하는 컨셉
- synthesize: 합성하다
- treatment가 없을 때의 treatment group의 패턴을 control group을 활용해서 예측
- treatment 이전(pre-intervention)에 대한 예측 모델 생성
= Pseudo-Counterfactual을 예측하는 것 - treatment 이후의 트렌드와 예측 차이로 인과 효과를 추론
- treatment 이전(pre-intervention)에 대한 예측 모델 생성
- control group이 없어도 활용 가능 → Pseudo-Counterfactual Approach
- ex. A 도시의 정책 효과 분석
- A와 비슷한 B, C, D 도시 데이터를 기반으로 Synthetic control 모델링
- Ceteris paribus
- A 도시의 정책(treatment) 이후 효과를 관찰한 후, 모델의 예측 결과와 차이 비교 ⇒ 인과 효과 추론
- RCT나 준실험 Design을 활용하여 검증을 한다면 best
- A와 비슷한 B, C, D 도시 데이터를 기반으로 Synthetic control 모델링
- ex. A 도시의 정책 효과 분석
Session 11-4
Netflix의 추천 알고리즘 평가
- test셋의 효과가 실제 business에도 적용되기 위해서는, 새로운 알고리즘을 도입했을 때 기존과 동일한 방식으로 반응할 것이라는 가정이 필요함
- 사람들은 fix 되어 있지 않음
- 여러 요인에 의해, 새로운 알고리즘을 도입했을 때 기존과 동일한 방식으로 반응하지 않을 수 있음
- offline experiment → A/B test
- 과거 데이터를 기반으로 모델을 검증: offline experiment
- 과거 알고리즘과 신규 알고리즘 A/B test 적용

예측 모델도 Selection Bias에서 자유롭지 않음
- 현실의 많은 데이터들은 여러 가지 요인들에 의해 이미 선택된 경우가 많음 → selective lables
- 예측 모델링에서도 인과 추론의 관점이 필요하고 research design이 중요함
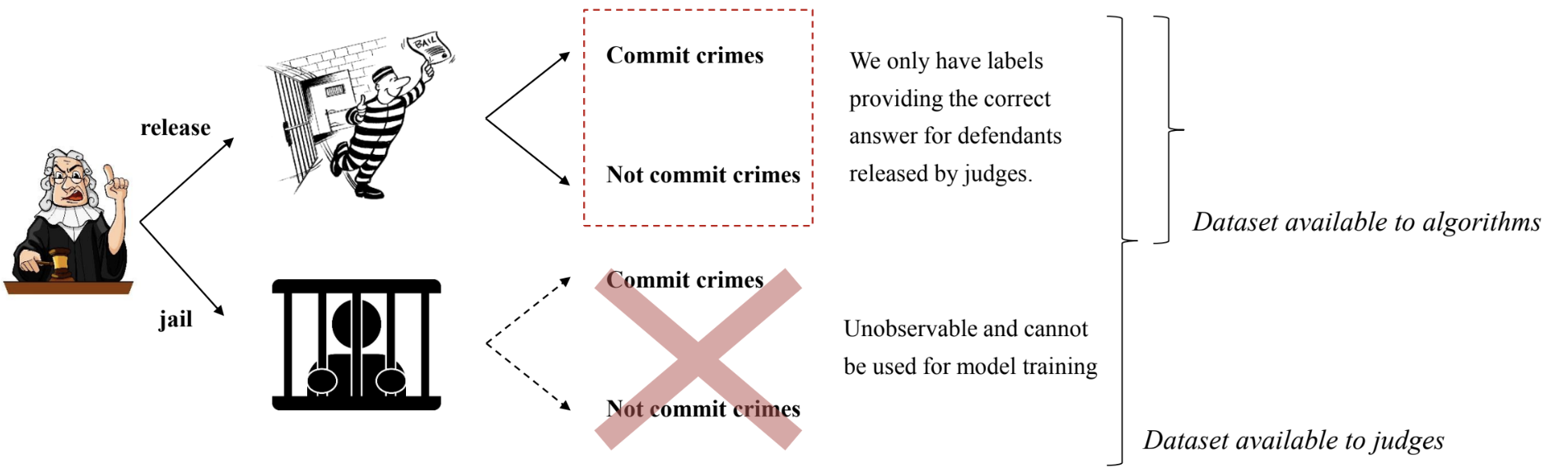
- ex. 재판의 판결
- 상황: 판사의 보석 석방/구금에 대한 결정
- 목적: 재범율 최소화
- 문제: 보석 석방된 사람들의 재범율 데이터만 존재, 구금된 사람들의 데이터는 관찰되지 않음
- 해결방안:
- randomized experiment 활용 → simulation이 아닌 현실이기 때문에 적용이 어려움
- 현실적인 상황: 가지고 있는 데이터만 활용 가능 (보석 석방된 사람들의 재범율) → simulation
- 석방된 사람들의 재범율과 알고리즘을 통해 석방된 사람들의 재범율 비교 → 두 집단이 비교 불가능
- 판사들이 이미 재범율이 낮다고 판단한 사람들을 기반으로 알고리즘이 예측했기 때문에, 알고리즘 성능이 더 좋다고 할 수 밖에 없음
- 연구 Design: 판사들의 성향에 따라 석방률이 다른 것을 활용
- 관대한 판사가 석방한 사람들 중, 알고리즘이 예측한 재범율이 높은 사람들을 제외 → 두 판사의 재범율 비교
- 석방된 모든 사람 vs 예측으로 석방된 사람보다 훨씬 비교 가능함
- 판사의 판결 성향과 피고가 배정되는 판사가 random하다는 가정이 필요함
반응형
'Causal inference' 카테고리의 다른 글
| Part 2. Selected Topics for Everyone (1) | 2023.09.13 |
|---|---|
| Part 1. 03~04 (1) | 2023.09.07 |
| Part 1. 01~02 (0) | 2023.08.30 |
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 9 (0) | 2023.08.29 |
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 7/8 보충 (0) | 2023.08.22 |




댓글