인과추론의 데이터과학. (2021, Oct 5). [Session 9-1] 도구 변수 (Instrumental Variable) [Video]. YouTube.
인과추론의 데이터과학. (2021, Oct 5). [Session 9-2] 도구 변수의 활용 사례 [Video]. YouTube.
인과추론의 데이터과학. (2021, Oct 5). [Session 9-3] 도구 변수의 활용 팁 [Video]. YouTube.
Session 9-1
Instrumental Variables
- Quasi-Experiment를 하기 어려울 때 이용하는 도구
- 활용하기가 까다로운 점이 있음 → 적절한 가정을 판단하기 어려움
Three perspectives on causation
- Potential outcomes framework
- 인과추론을 방해하는 요인: selection bias
- treatment 그룹과 control 그룹이 비교 가능하지 않아서 발생
- 관찰되지 않은 요인은 treatment와 관계가 없어야함 → Ceteris Paribus
- 인과추론을 방해하는 요인: selection bias
- Structural causal model
- 인과추론을 방해하는 요인: backdoor path
- do operator → backdoor path 제거 → 인과 효과 추정
- Statistics (Regression)
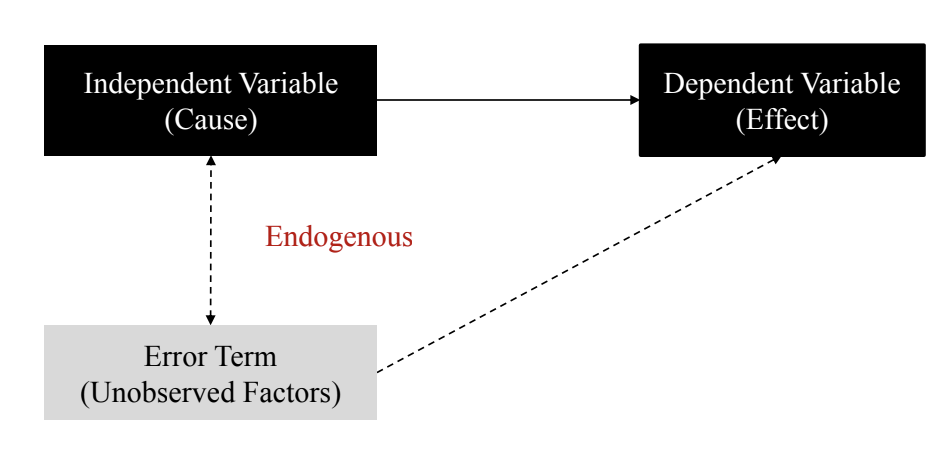
- 인과추론을 방해하는 요인: endogeneity (내생성)
- 원인 변수와 에러 조건 간에 상관성이 있는 것
- 인과추론을 방해하는 요인: endogeneity (내생성)
⇒ selection bias와 backdoor path 없다 = 원인 변수와 에러 조건 간에 상관관계가 없다
Endogeneity in regression
- Exogenous해야 인과관계를 해석가능 → Unbiased Estimate
- Error term: 관찰되지 않은 요인
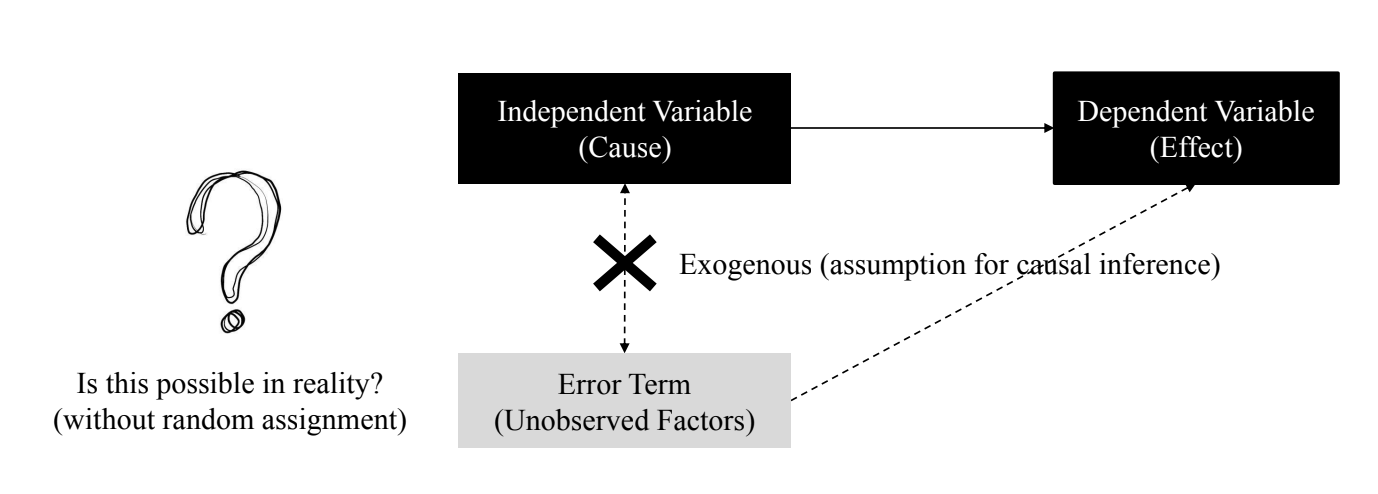
- 현실적으로 Exogenous한 원인 변수를 찾는 것이 가능할까? → 쉽지 않음
- 모든 것은 Endogenous(내인성)하다고 가정 ⇒ 귀무가설
Instrumental Variable (IV)
- 독립 변수는 아래 그림과 같이 error term과 Exogenous한 부분과 Endogenous로 나뉘어질 것
- 이것을 인위적으로 가려내는 것이 도구 변수의 역할
- 원하는 부분(Exogenous)만 가려내기 때문에 도구 변수로 불림

Approach 1. Two-Stage Least squares
- Stage 1: 도구 변수(\(Z\))로 독립 변수(\(X\))를 예측 ⇒ \(\hat{X}\)
- \(\hat{X} = a_0 + a_1Z + \epsilon\)
- \(\epsilon\) : error term
- \(\hat{X} = a_0 + a_1Z + \epsilon\)
- Stage 2: 예측된 독립 변수(\(\hat{X}\))로 종속 변수(\(Y\))를 예측
- \(Y = b_0 + b_1\hat{X} + \epsilon'\)

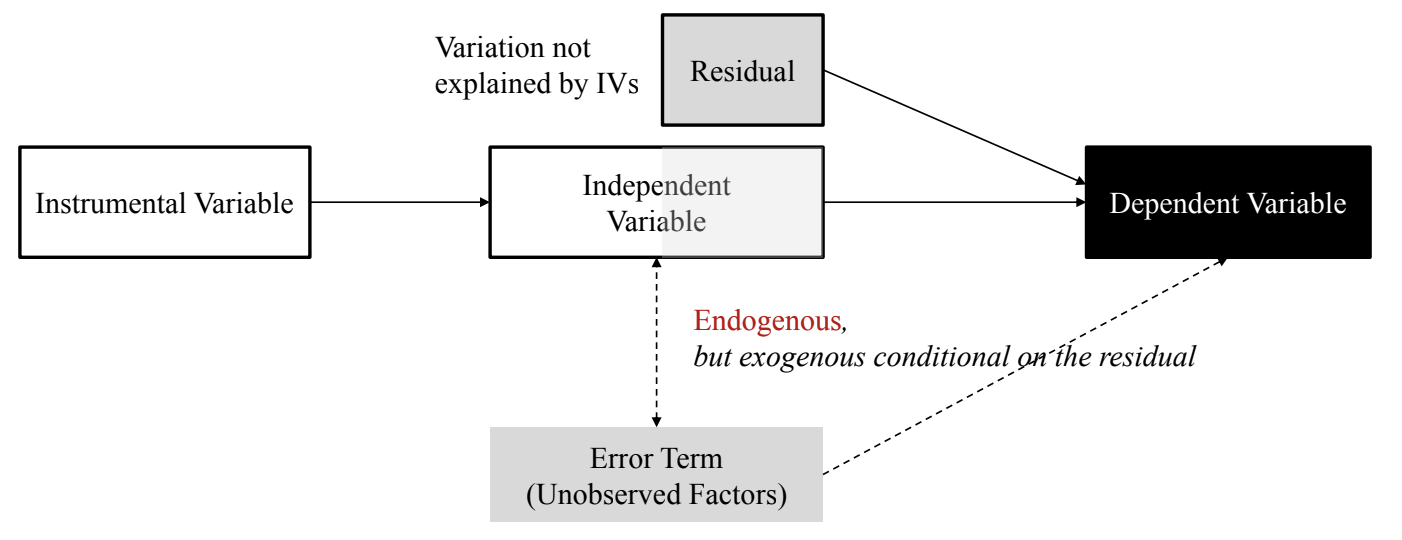
Approach 2. Control Function
- Endogenous한 부분을 통제 변수로 넣는 방식
- \(\epsilon\): residual
- 잔차(residual)을 conditioning한다면 conditional Exogeneous가 될 수 있음
- Basic idea: 아래 두 식의 error term이 상관관계가 있다.
- \(X= \gamma Z + v\)
- \(Y=\beta X + u\)
- \(E(Y|Z,v) = \beta E(X|Z,v) + E(u|Z,v) = \beta X + E(u|v) = \beta X + \rho v\)
- \(Z\)는 \(u\)와 독립적이어야 도구 변수가 Exogeneous한 부분만 예측 가능 ⇒ \(E(u|Z,v) = E(u|v)\)
- \(\rho\) : \(corr(u, v)\)
- Example: Heckman-type selection model → 계량경제학에서 중요한 개념
- Stage 1: sample selection(binary)을 결정 (probit model)
- \(Pr(S=1) = \phi{(\gamma Z + v)}\)
- Stage 2: truncated model
- 정규분포를 따르는 probit model하에서, control function을 inverse Mills ratio로 변환 가능
- \(Y = \beta X + Controls + u\)
→ \(E(Y|S=1) = \beta X + \rho\lambda\)
→ \(Y = \beta X + \rho\lambda + \epsilon\)
→ \(E(Y|S=1) = \beta X + E(u|S=1)\)
- Stage 1: sample selection(binary)을 결정 (probit model)
Identification Assumption for IV
- Identification Assumption: 연구 디자인에서 선택 편향을 없앨 수 있는 가정
- 가정
- 도구변수로 예측한 독립 변수도 error term과 상관관계가 없음 → 도구변수가 error term과 상관관계가 없어야함
- 도구변수는 독립 변수(원인 변수)에 대해 충분히 설명 가능해야함
Violation을 야기하는 case
- Exclusion Restriction
- confounder
- direct effect of IV

- Exogeneity assumption
- other mediators between IV and the outcome
- 통계적으로 보면 \(U, U_1, U_2\)는 모두 error term으로 고려가 되기 때문에 Exclusion Restriction와 Exogeneity assumption는 크게 구분되지 않음

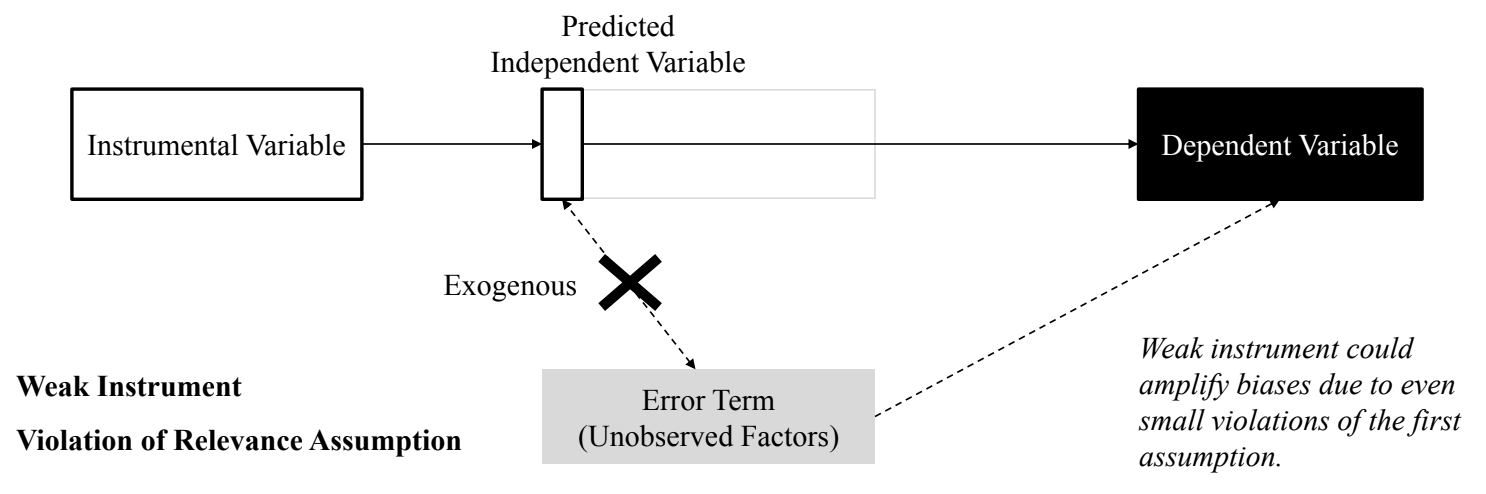
- Relevance assumption
- weak instrument : 도구변수가 원인 변수의 너무 작은 부분만 예측하는 경우
- 정교하게 Exogeneous한 부분만 잘라내면 문제가 되지 않음
- Exclusion Restriction과 Exogeneity assumption과 같이 다른 가정이 위배되면 문제점이 크게 증폭됨
- 현실에서는 어떤 부분이 Endogeneous하고 Exogeneous한지 모르기 때문에 어느 정도 오차가 생길 수 있음 → 오차에 robust하기 위해서는 weak instrument를 피해야함
- 도구변수가 너무 강하게 원인 변수를 예측하면 Endogenous할 수 있음
- weak instrument : 도구변수가 원인 변수의 너무 작은 부분만 예측하는 경우
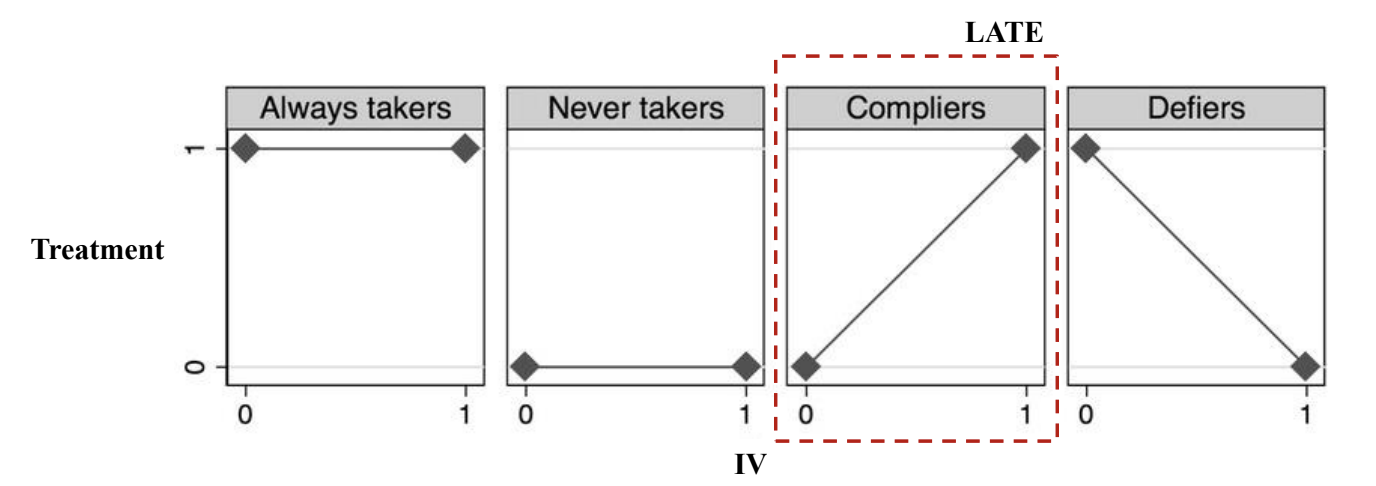
Local Average Treatment Effect (LATE)
- 원인 변수로 추정된 효과: ATE
- 도구변수로 추정된 효과: LATE (≠ ATE) → 도구 변수의 한계
- Exogeneous한 부분만 떼어내서 추정한 결과이기 때문
- Defiers가 없는 상태에서 추정한 ATE
- never takers: treatment를 받지 않기 때문에 관심 없음
- always takers + compliers 조합
- Compliers: 도구변수에 따라 변화되는 그룹
- Defiers: 도구변수와 반대로 발생하는 그룹
- monotonicity assumption : defiers가 없어야함
- LATE = ATE가 되기 위한 조건
- always takers가 없어야함
- homogeneity assumption: 모든 subject에 대해서 treatment가 같아야함
- randomness of IVs
Session 9-2
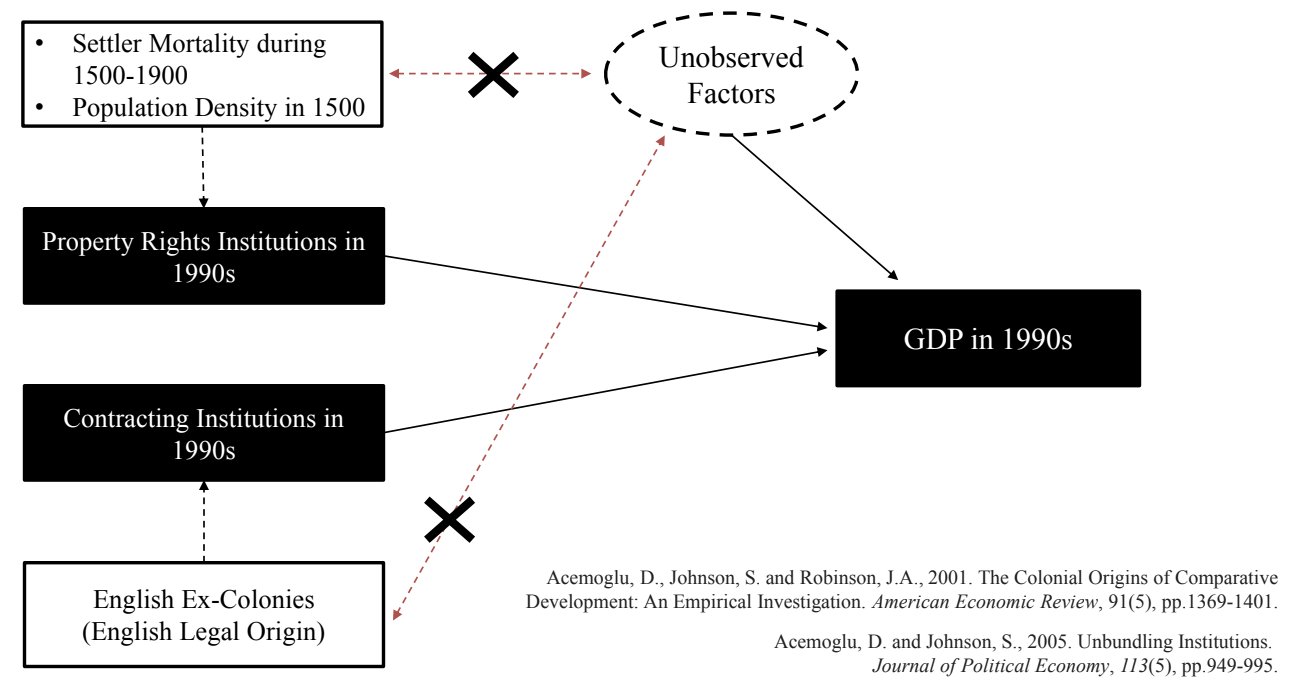
Example 1. Economic growth
- 문제: 1990년대 사유재산 제도와 계약 제도가 GDP(경제 성장)에 미치는 영향
- 관찰할 수 없는 요인은 제도에 영향을 미칠 수 있음 → 원인 변수들은 내생적 (Endogeneous)
- 도구변수 활용
- 사유재산 제도: 침략국의 식민지에서의 사망률과 인구 밀도 활용
- 계약 제도: 유럽 대륙 국가들의 식민 지배 여부 활용
- 미국 지배 → 영미법 (판례 중심) ⇒ 발전됨
- 프랑스, 스페인 등 지배 → 대륙법 (고정된 성문법을 따름)
- 한국: 네덜란드의 영향을 받은 일본의 영향
- 결과
- 사유재산 제도가 경제 성장에 큰 영향을 미쳤다.
- 사유재산 제도가 미치는 인과 효과를 배제하면 저소득 국가의 경제 규모는 유럽, 아메리카 국가와 유의미한 차이가 없다고 밝힘
Example 2. Noncompliance in Randomized Experiments
- 무작위 실험에 도구변수를 활용하는 이유: Noncompliance 문제를 해결하기 위함
- Noncompliance 문제: treatment 그룹의 일부가 실제로 treatment를 받지 않을 때 발생
- Intention-to-Treat (ITT) effect
- treatment 그룹과 control 그룹 간의 차이를 비교함으로써 추정하고자 의도하는 효과
- 재택 근무의 효과 실험 (중국에서 진행)
- 문제: 재택 근무가 노동자 생산성에 미치는 영향
- 도구변수: 뽑기로 treatment(재택 여부)를 결정
- 원인 변수: 재택 효과
- 결과 변수: 노동자 생산성

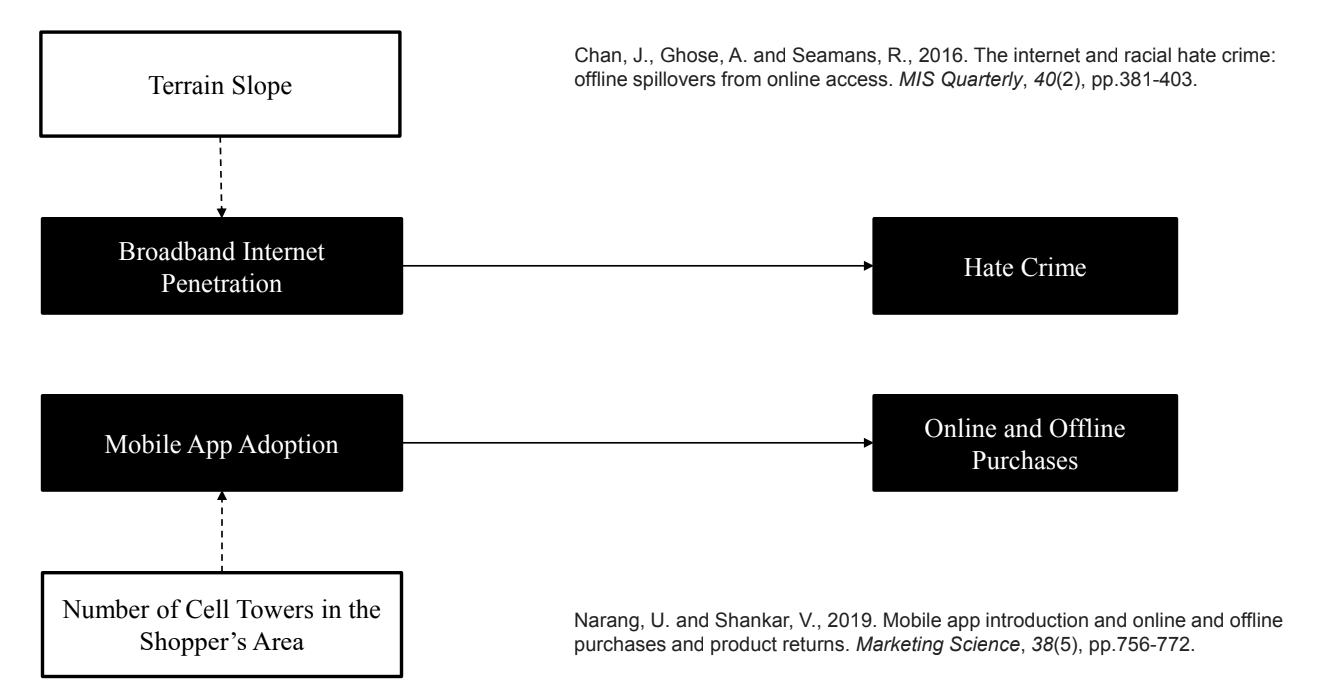
Example 3. Regional IVs
- 문제 1: 인터넷 보급이 혐오 범죄에 미치는 영향
- 도구변수: 지형적인 기울기
- 언덕이 많을 수록 인터넷 선을 설치하기 까다롭다고 생각
- 도구변수: 지형적인 기울기
- 문제 2: 모바일 앱 채택이 온/오프라인 제품 구매에 미치는 영향
- 도구변수: 소비자가 사는 지역에서의 기지국 숫자
- 미국은 지역에 따라 신호가 안잡히는 곳이 많음
- 도구변수: 소비자가 사는 지역에서의 기지국 숫자
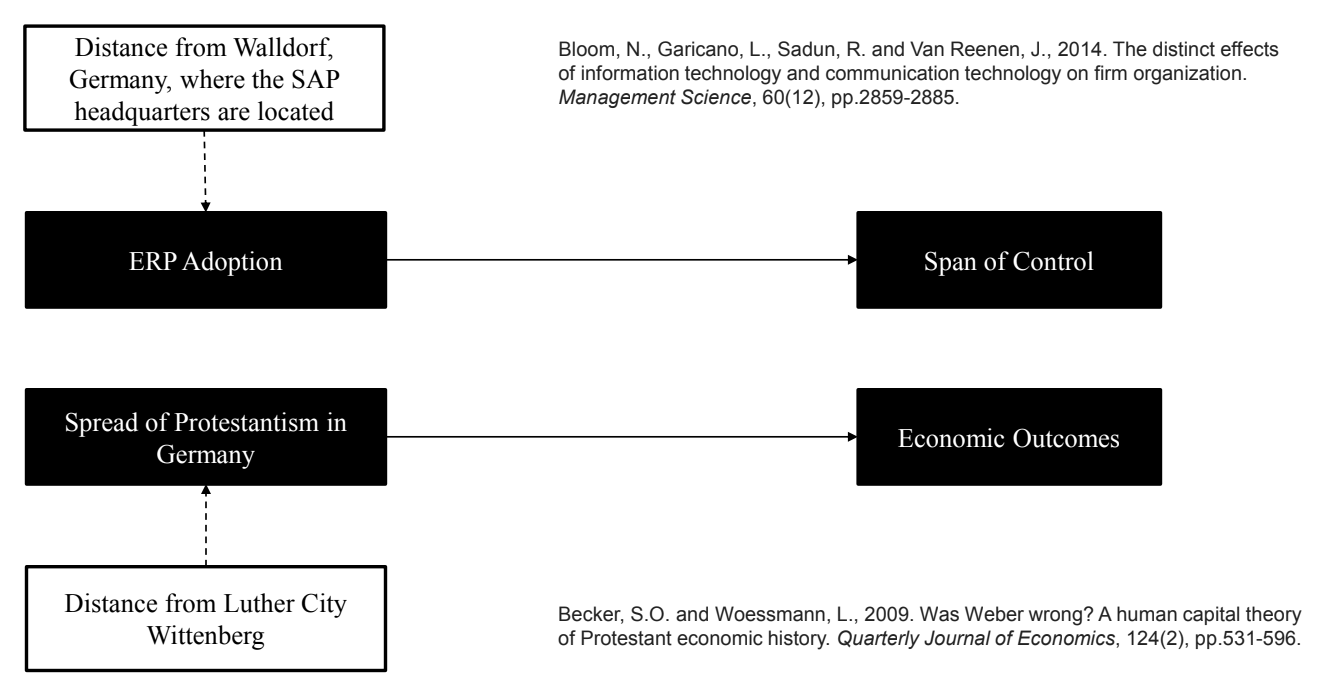
Example 4. Geographical Proximity-Based IVs
- 지리적 근접성 기준
- 문제 1: ERP의 도입이 관리자의 관리 범위에 미치는 영향
- 도구변수: 독일에 있는 SAP 본사와의 거리 (유럽에서 진행한 연구)
- 문제 2: 독일에서 개신교의 확산이 경제 성장에 미치는 영향
- 도구변수: 루터의 도시인 부텐베르크와의 거리
- 루터의 종교 개혁이 부텐베르크에서 시작됨
- 도구변수: 루터의 도시인 부텐베르크와의 거리
Example 5. Macro/Cohort Trends as IVs
- 문제 1: 도시에서의 실업률이 온라인 구직 시장에서의 노동자 공급에 미치는 영향
- 도구변수: 미국 전체 고용률의 trend (Macro)
- 문제 2: 모바일 로열티 프로그램 가입 여부가 로열티 포인트 사용에 미치는 영향
- 도구변수: 해당 고객과 같은 지역에 사는 같은 코호트의 5G 가입률

Example 6. Peers’ Environments as IVs
- 문제 1: 친구의 러닝 행동이 사용자의 러닝 행동에 미치는 영향
- 도구변수: 친구가 사는 지역의 날씨
- 문제 2: 친구의 체크인이 사용자의 방문에 미치는 영향
- 도구변수: 친구의 친구의 체크인 (친구의 친구는 사용자에게 남)

Session 9-3
Reduced form
- 도구변수로 바로 결과변수를 예측하려고 하는 것
- \(Y = \gamma_0 + \gamma_1Z + \delta\)
- Exclusion Restriction에 따르면 도구변수가 원인 변수를 통해서만 결과 변수에 영향을 미쳐야한다고 했음
- 도구변수가 결과 변수에 영향을 미쳐야 의미가 있음
- 아래 그림에서 reduced form(\(\gamma_1\))가 0이라면 \(\beta_1\)도 0
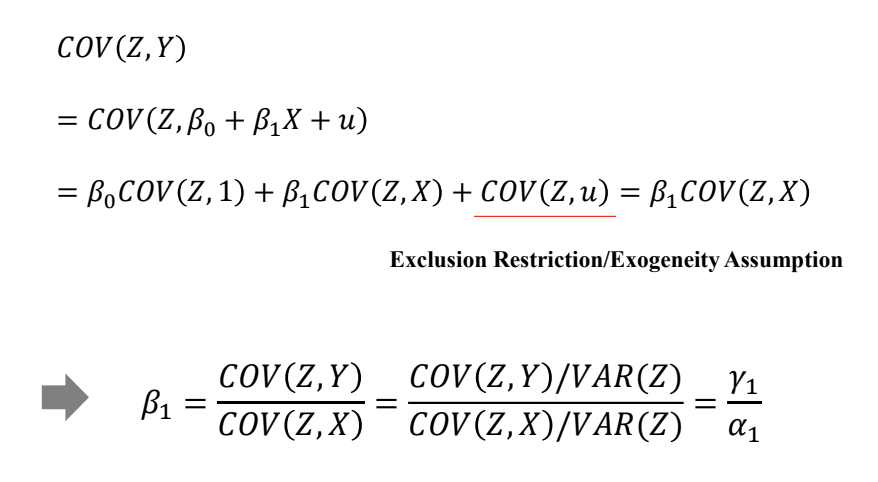
IV 분석을 리포트하는 법
- Step 1: 도구변수에 대해 통계적인 테스트 수행
- Step 2: 도구변수의 이론적 타당성을 정당화
- Step 3: 도구변수에 대해 robustness check 또는 sensitivity analysis 진행
- Stpe 4: LATE or ATE 중 어떤 것을 추정하는 것인지에 대해 명확하게 discuss
통계적 테스트
- relevance assumption은 통계적으로 검증이 가능 (ex. Stock-Yogo가 개발한 통계 활용)
- relevance assumption: not weak instrument
- exclusion restriction과 exogeneity assumption은 증명이 불가능함
- 도구변수가 error term과의 상관관계가 없어야한다는 것
- 모든 통계적 테스트들은 주관적임
- 도구변수의 적절성을 검증하기 위해 도구변수의 적절성을 가정해야할 수 밖에 없음
- ex. Hausman test (하우스만 테스트)
- 내생성이 없다고 가정한 상태에서 OLS의 추정치와 내생성이 있다고 가정한 상태에서 도구변수의 추정치가 얼마나 다른지 테스트한 것
- 중요한 가정: 도구변수가 완전하다
⇒ 사용하지 않는 것을 추천 (모든 것은 내생성을 가진다고 가정하는 것이 현실적임)
- ex. Sargan-Hansen J test (over-identifying)
- exclusion restriction, exogeneity assumption에 대한 테스트
- K-1개의 도구변수를 바탕으로 계산한 error term(stage2)과 도구변수의 상관관계를 검증
- 중요한 가정: 도구변수의 적절성을 검증하기 위해 1개 뺀 나머지 도구변수가 완전하다고 가정
⇒ 필수적으로 report하는 것이 좋다.
도구변수의 이론적 타당성을 정당화
- 통계적인 테스트가 도구변수 활용에 있어서 필요충분조건은 아님
- 대부분의 논문은 이론적 타당성을 정당화하는 것이 대다수임 → 이론적 뒷받침이 중요함
- causal diagram을 활용하는 것도 도움이 됨

반응형
'Causal inference' 카테고리의 다른 글
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 11 (0) | 2023.09.05 |
|---|---|
| Part 1. 01~02 (0) | 2023.08.30 |
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 7/8 보충 (0) | 2023.08.22 |
| [KSSCI 2021] 인과추론의 데이터 과학 - 사전학습자료 (0) | 2023.08.15 |
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 7 (0) | 2023.08.08 |




댓글