반응형
인과추론의 데이터과학. (2021, Jun 20). [사전학습자료 1] 인과추론의 어려움 [Video]. YouTube.
인과추론의 데이터과학. (2021, Jun 22). [사전학습자료 2] 인과추론의 목적 [Video]. YouTube.
인과추론의 데이터과학. (2021, Jun 25). [사전학습자료 3] 인과추론 관점에서 회귀분석 이해하기 [Video]. YouTube.
사전학습자료 1
상관관계, 인과관계
- 상관관계: 함께 일어나는 변화
- 아이스크림 판매량 ~ 익사자 수
- 인과관계: 원인과 결과
- 여름 ~ 아이스크림 판매량
- 여름 ~ 익사자 수

사회과학 사례
- 내가 홍보한 상품을 내 친구가 구매했다면 그건 내 덕분일까?
- 취미/특성의 유사성 (homophily) → 끼리끼리 어울린다. ⇒ 상관관계
- 동료 효과 (peer effect; social influence) ⇒ 인과관계

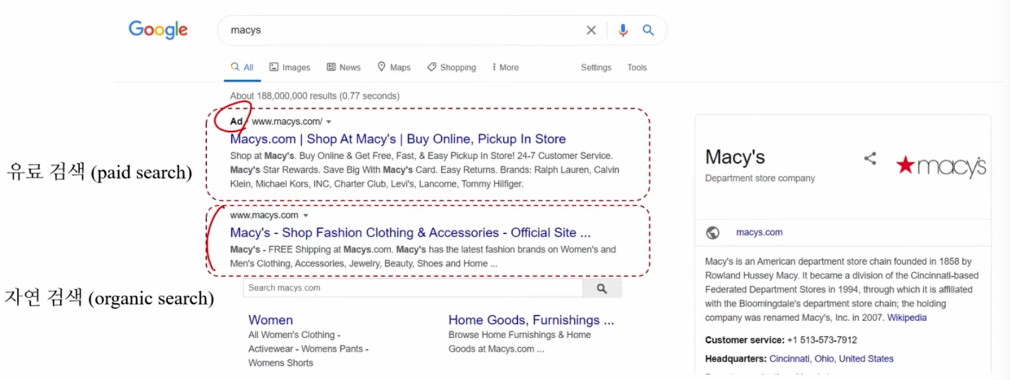
- 검색엔진에 홈페이지 광고를 내는 것이 효과가 있을까?
- 시나리오
- 기존 고객은 자연 검색으로 진입하고, 비고객만 유료 검색으로 진입할 수 있음
- 기존 고객이 유료 검색으로 진입할 수 있음
- 문제점
- 비고객과 기존 고객을 추적하는 것이 어려움
- 연구 결과 (Blake et al. 2015, Econometrica)
- 검색 광고와 수익률 간의 높은 상관관계를 기반 → 높은 ROI (1,600%~4,000%)
- 내생성을 고려한 인과관계 기반 → 낮은 ROI (-20% ~ -60%)
- 시나리오
- 사업 다각화(diversification)는 유효한 사업전략인가?
- 많은 연구 결과에서 “다각화와 기업 가치 간에 음의 관계가 있다.”라고 결론이 나왔음
- Lang and Stulz 1994, Journal of Political Economy
- 다각화를 한 기업 vs 다각화를 하지 않은 기업
- 다각화 전략에 대한 선택 편향을 고려한 결과, “다각화는 기업 가치와 유의한 관계가 없거나, 양의 관계를 갖는다”라고 결론이 나옴
- Campa and Kedia 2002, Journal of Finance
- 다각화를 한 기업과 하지 않은 기업 간에는 많은 차이가 있다고 판단 → 선택 편향 제거
- 많은 연구 결과에서 “다각화와 기업 가치 간에 음의 관계가 있다.”라고 결론이 나왔음
편향의 종류
- 데이터/통계분석에서 상관관계와 인과관계를 헷갈리게 하는 모든 요인을 내생성(endogeneity)이라고 부름
- 회귀 분석 관점 내생성의 요인
- Omitted variable bias: 선택편향의 회귀분석 버전
- Simultaneity bias (reverse causality bias): 역-인과관계로 인해 관찰되는 상관관계
- Measurement error: 측정 변수의 오차가 있는 경우 추정 결과가 편향될 수 있다는 것을 의미
- 측정오차가 체계적인 경우에는 상대적으로 해결하기 쉽지만, 그렇지 않은 경우 보다 복잡한 통계적 보정이 필요
사전학습자료 2
인과추론을 위한 첫 번째 단계
- 분석 대상 구체화하기: 구체적으로 무엇을 분석할 것인가?
- 분석 대상 간의 관계 명확히 하기: 선행 변수(X)는 무엇이며, 후행 변수(Y)는 무엇인가?
사회과학 인과추론의 목적
- 사회과학에서의 인과추론의 본질: 선행변수에 대한 개입(intervention)과 조정(adjustment)
- “우리는 연구 대상에 행해질 수 있는 행동을 특정할 수 없는 처치(treatment)에 대해서 인과적 효과를 추정할 수 없다.”
- Rubin 교수님: Potential outcomes framework 창시자
인과추론을 위한 두 번째 단계
- 분석 목적 명확히 하기
- 선행 변수(X)에 대한 개입과 조정 → 인과추론 방법론
- 후행 변수(Y)에 대한 정밀한 예측 → 예측 방법론
- 인과추론 방법론과 예측 방법론은 상호 보완적인 관계
- 인과추론: 예측을 하기 위한 변수 선정에 도움을 줌
- 예측 방법론: 원인이 될 수 있는 후보군을 추릴 수 있음

- Example (SNS 마케팅)
- X: 인플루언서 (동료 효과) → Y: 주변인의 구매 여부
- Q) 인플루언서를 섭외하여 바이럴 마케팅을 하고 싶다면? → 인과추론 방법론
- Q) 제품 구매 확률이 높은 이용자들을 찾아서 타겟 마케팅을 하고 싶다면? → 예측 방법론 (ML, Recsys)
인과추론에서 메커니즘 규명이 중요한 이유
- 효과적인 개입 전략 수집을 위해 메커니즘에 대한 규명이 중요함
- ex. 제임스 린드 박사의 괴혈병 치료제
- 치료제가 나타나기 50년 전에 레몬, 오렌지가 괴혈병 치료에 도움을 주는 것을 알고 있었음
- But 레몬과 오렌지의 어떤 부분이 괴혈병 치료에 영향을 주는지 몰랐음
- 처음에 산도가 영향을 준다고 판단하여 레몬즙을 가열하여 치료함 → 비타민C 증발
- 이후, 비타민 C가 영향을 주는 것을 발견함
사전학습자료 3
회귀분석이 이상적인 이유
- 이상적 추정치인 BLUE란?
- BLUE (Best Linear Unbiased Estimator): 통계적으로 효율적이고, 비편향적이며, 일관적인 추정치

- 통계적 추론의 판단 기준
- 평균적으로 얼마나 모집단에서의 참값에 가깝게 추정하는가? → 통계적 비편항성 + 일관성
- 무작위로 반복적으로 샘플을 선정하여 추정했을 때 얼마나 정밀하게 추정하는가? → 통계적 효율성
인과추론에서 내생성이 중요한 이유
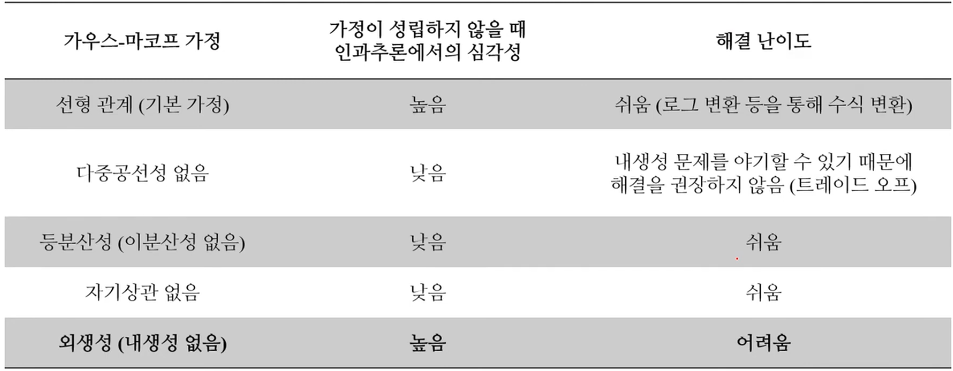
- 가우스-마코프 가정이 성립하지 않으면?
- 선형 관계 (기본 가정) → BLUE 성립 불가능
- 다중공선성 없음 → 통계적으로 비효율적임
- 등분산성 (이분산성 없음) → 이분산성인 경우, 평균적으로는 비편향적이지만(=추정치에 가까움) 통계적으로는 비효율적임 (값의 널뛰기가 심함 → 분산이 커짐)
- 자기상관 없음 → 자기상관과 관계없이, 평균적으로는 비편향적이지만 통계적으로 비효율적임
- 외생성 (내생성 없음) → 통계적 편향성이 생김 (=완전 잘못 추정하고 있는 것) + 통계적 일관성을 보임
- 내생성: 독립 변수와 오차항 간에 상관관계가 있도록 조정함
- 비일관성: 통계적 편향성이 생기고, 샘플 수가 커질수록 내생성의 문제를 정확하게 잘못 추정함 (값의 변동폭이 줄어듦)
- 어떤 가정을 위배하는 것이 더 심각한 문제를 야기할까?

- 회귀분석에서 이분산성과 자기상관을 해결하기 위한 ‘쉬운’ 방법
- 강건한 표준편차 (robust standard errors)
- 군집 표준편차 (clustered standard errors)
- 회귀분석에서 내생성을 해결하기 위한 ‘쉬운’ 방법
- 데이터와 통계적(수학적) 기법을 통해 해결할 수 있는 ‘쉬운’ 방법이 없음
- 적절한 실험설계를 통해서만 내생성을 배제 가능 → Ceteris Paribus
- 무작위 통제실험, 준실험, 인과 그래프
- 내생성 문제를 해결해야 회귀분석에서의 추정치를 인과관계로 해석 가능
- 인과추론에서는 통계적 비편향성이 통계적 효율성보다 중요하다.
- 통계적 비편향성이 위배되는 것이 심각성이 높다.
반응형
'Mathematics > Causal inference' 카테고리의 다른 글
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 9 (0) | 2023.08.29 |
|---|---|
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 7/8 보충 (0) | 2023.08.22 |
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 7 (0) | 2023.08.08 |
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 3, 4 (0) | 2023.08.01 |
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 2 (0) | 2023.07.25 |




댓글