젠스 알브레히트, 시다르트 라마찬드란, 크리스티안 윙클러, 『파이썬 라이브러리를 활용한 텍스트 분석 Blueprints for Text Analytics Using Python』, 심상진, 한빛미디어-OREILLY(2022), p177-212.
Learned
MultiLabelBinarizer
- One-hot Encoding을 할 경우 MultiLabelBinarizer를 쓰는 것을 권장
- OneHotEncoder는 범주형 특성에만 적합
- Multi-label Classification에서도 활용 가능
Bag Of Words (BOW)
- BOW를 이용해 문서 간의 유사성을 구할 때, 문서 벡터 간의 각도를 유사성의 척도로 활용하는 방법을 추천
- 스칼라곱은 벡터의 크기(문서의 단어 수)에 민감함
- 유클리디안 거리는 고차원 벡터 공간에서 유용하지 않음
$$cos(a, b) = {{a \cdot b} \over {||a|| \cdot ||b||} } = { {\sum{a_ib_i}} \over { {\sqrt{\sum{a_ia_i}}} {\sqrt{\sum{b_ib_i}}} } }$$
특성 차원 축소
- 연산량은 특성의 개수에 따라 제곱으로 커짐 -> \(O(N^2)\)
- 매개변수 or 벡터화 방법을 변경할 때는 항상 특성 차원의 수를 관찰하는 것이 좋음
- TfidfVectorizer에서 불용어 제거(stop_words), 최소 빈도(min_df) 및 최대 빈도(max_df)를 제한할 수 있음
- TF-IDF 방법으로 비정규 용어 빈도 or 결과 벡터를 정규화하여 성능을 개선할 수 있음
- 최소 빈도로 제한하는 경우, 새 문서에 등장하면 빈도 수가 커질 수 있기 때문에 정보의 유실이 발생 가능
- 문서가 추가되는 경우 기존에 산출한 특성 수가 너무 적을 수 있음
- 언어 분석(linguistic analysis)으로 차원을 줄일 수 있음
- 특정 품사로 제한(ex. 명사, 형용사 등)
- 표제어 추출(lemmatization)
- 소설의 경우 시제가 중요할 수 있음 -> 분석 및 데이터에 맞게 텍스트 변환을 선택
- 일반적으로 자주 사용하는 단어 제거
- 중요한 의미를 전달하는 단어가 포함될 수 있음 -> 다른 방법을 사용한 후, 추가적으로 수행하는 것을 권장
대규모 말뭉치 문서 유사도 산출
- 준대각 요소만 계산 (문서 유사성 관계가 대칭적이기 때문에 가능) -> 계산할 요소의 수가 절반으로 감소
- 개별 요소를 계산하는 대신 작은 블록 단위로 계산
- 10,000 X 10,000개의 유사도 부분 행렬을 한 번에 계산 -> RAM 크기에 적합한 차원을 선택
- 데이터 지역성을 활용하여 필요한 행렬의 요소가 이미 CPU 캐시에 있을 가능성이 큰 장점이 있음
- 대각선 블록은 흰색 요소와 대각선 요소를 중복 계산함 (검정색 부분과 겹칠 수 밖에 없기 때문)
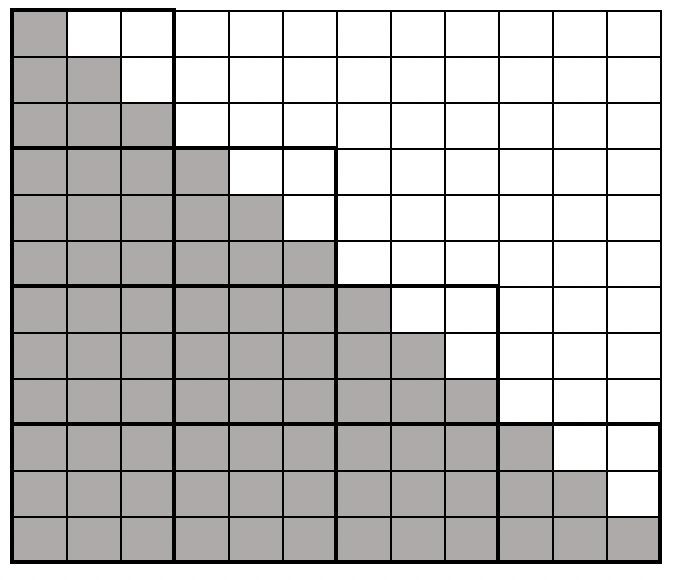
- 전체 데이터셋에 계산을 하기 전에 단일 계산을 실행하고 전체 알고리즘의 런타임과 메모리양을 추정하면 좋음
- 복잡성(선형, 다항식, 지수)이 증가함에 따라 런타임과 메모리가 어떻게 증가하는지 이해해야됨
Reference
- MultiLabelBinarizer
- tistory inline 수식
- 일반적으로 자주 사용하는 영어 단어
반응형
'NLP' 카테고리의 다른 글
| Chapter 7. 텍스트 분류기 (0) | 2023.09.29 |
|---|---|
| Chapter 6. 텍스트 분류 알고리즘 (0) | 2023.03.26 |
| Chapter 4. 통계 및 머신러닝을 위한 텍스트 데이터 준비 (0) | 2023.03.26 |
| Chapter 3. 웹사이트 스크래핑 및 데이터 추출 (0) | 2023.03.26 |
| Chapter 2. API로 추출하는 텍스트 속 통찰 (0) | 2023.03.26 |




댓글