젠스 알브레히트, 시다르트 라마찬드란, 크리스티안 윙클러, 『파이썬 라이브러리를 활용한 텍스트 분석 Blueprints for Text Analytics Using Python』, 심상진, 한빛미디어-OREILLY(2022), p213-249.
Learned
SVM
- 랜덤 포레스트 대비 희소 데이터의 분류 및 예측 작업에 더 적합함 ➡️ 텍스트 데이터로 작업할 때 선호됨
- 숫자로만 이루어진 입력 특성으로 작업할 때 적합
- 혼합된 입력 특성(ex. 범주 + 수치)인 경우, 다른 알고리즘을 쓰는 것이 좋음
Linear SVC vs SVC vs SGDClassifier
- LinearSVC
- sklearn.svm.LinearSVC
- liblinear 구현을 기반 (C++ 오픈 소스 라이브러리)
- SVC, SGDClassifier보다 훨씬 빠름
- SVC
- sklearn.svm.SVC
- libsvm 구현을 기반 (C++ 오픈 소스 라이브러리)
- 다양한 커널 함수를 지원 (선형, 다항식, 방사형 기저 함수)
- SGDClassifier
- sklearn.linear_model.SGDClassifier
- 손실 함수를 hinge로 지정하면 선형 SVM과 동일
Confusion Matrix plot
- sklearn < 1.2
- sklearn >= 1.2
from sklearn.metrics import ConfusionMatrixDisplay
import matplotlib.pyplot as plt
ConfusionMatrixDisplay.from_estimator(model, X_test, y_test, values_format='d', cmap=plt.cm.Blues)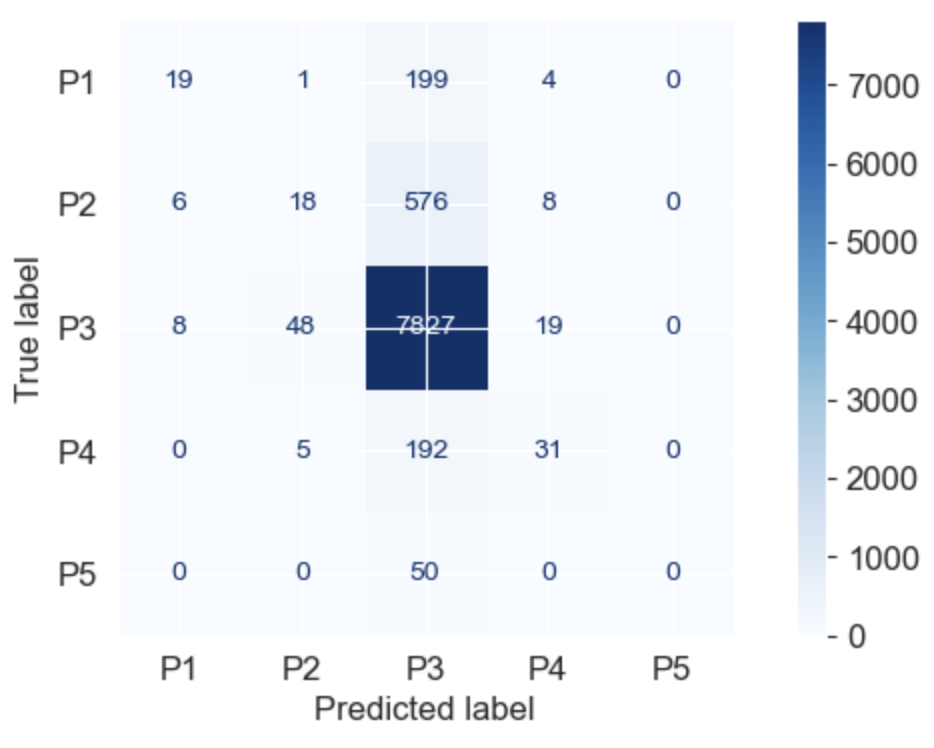
클래스 불균형
- 업 샘플링
- 소수 클래스의 관측치 수를 인위적으로 늘리는데 사용
- 복사본을 여러 개 추가하거나, SMOTE를 활용
- 다운 샘플링
- 클래스 균형을 맞추기 위해 샘플의 수를 제한하는 방법
- 정보가 유실되므로 일반적으로 잘 안쓰임
- imbalanced-learn 패키지나 NearMiss와 같은 추가 샘플링 기술도 있음
Question
- multi label classification은 어떻게 활용할 수 있을까?
- imbalanced-learn과 NearMiss 방법은 무엇이고 어떻게 사용할 수 있을까?
Reference
- SVM
- ConfusionMatrixDisplay
- Multi Label Classification
- imbalanced-learn: https://imbalanced-learn.org/stable/
- NearMiss
반응형
'NLP' 카테고리의 다른 글
| Chapter 8. 비지도 학습: 토픽 모델링 및 클러스터링 (0) | 2023.09.30 |
|---|---|
| Chapter 7. 텍스트 분류기 (0) | 2023.09.29 |
| Chapter 5. 특성 엔지니어링 및 구문 유사성 (0) | 2023.03.26 |
| Chapter 4. 통계 및 머신러닝을 위한 텍스트 데이터 준비 (0) | 2023.03.26 |
| Chapter 3. 웹사이트 스크래핑 및 데이터 추출 (0) | 2023.03.26 |




댓글