젠스 알브레히트, 시다르트 라마찬드란, 크리스티안 윙클러, 『파이썬 라이브러리를 활용한 텍스트 분석 Blueprints for Text Analytics Using Python』, 심상진, 한빛미디어-OREILLY(2022), p252-279.
Definition
- ground truth: 우리가 정한 정답, 모델이 우리가 원하는 정답으로 예측해주길 바라는 답
Using predict probability
- 올바르게 예측한 값과 틀린 값은 모델이 얼마나 확신을 갖고 결정했는지 histogram으로 확인
- Correct → 높은 확률로 결정되는 경우가 많았음
- Wrong → 모델이 헷갈려하는 경우가 많았음 (histogram에서 0.4-0.6에 빈도가 치중됨
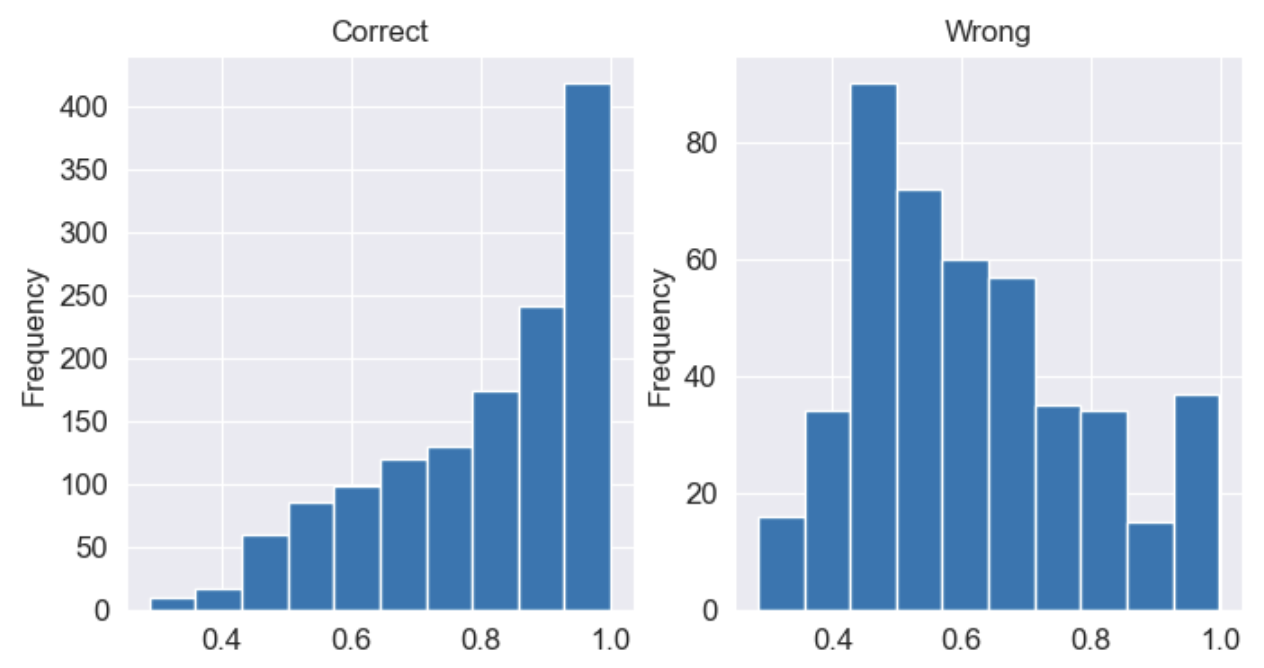
- 특정 임계치 (ex. 80%)를 기준을 넘는 결정만 고려해서 결과를 개선할 수 있음
- precision, recall, f1-score 확인
Feature Importance
- 모델이 특정 클래스를 예측하는데 긍정/부정적인 단어 or 토큰 확인
- 다중 클래스 분류 문제에서는 각 클래스가 다른 클래스와 가지는 관계 데이터를 기반으로 확인

LIME
- Local Interpretable Model-Agnostic Explanations
- 벡터의 변화에 따라 클래스에 어떤 구성 요소가 더 중요한지 덜 중요한지 시각화하는 프레임워크
- 특정 클래스에 긍/부정으로 생각하는 단어를 출력
- 모델 출력이 각 범주의 확률이 되어야 사용 가능
- 모델 자체와 독립적인 장점이 있음
- 고차원 특성 공간에서는 실용적이지 않음 (실행 시간이 오래 걸림)
- 특성 벡터의 일부분을 수정하기 때문에, 많은 예측을 수행해야하기 때문
from lime.lime_text import LimeTextExplainer
from sklearn.pipeline import make_pipeline
pipeline = make_pipeline(tfidf, svc)
class_names = ['APT', 'Core', 'Debug', 'Doc', 'Text', 'UI']
explainer = LimeTextExplainer(class_names=class_names)
exp = explainer.explain_instance(result.iloc[id]["text"], pipeline.predict_proba, num_features=6, top_labels=3)
exp.show_in_notebook(text=False)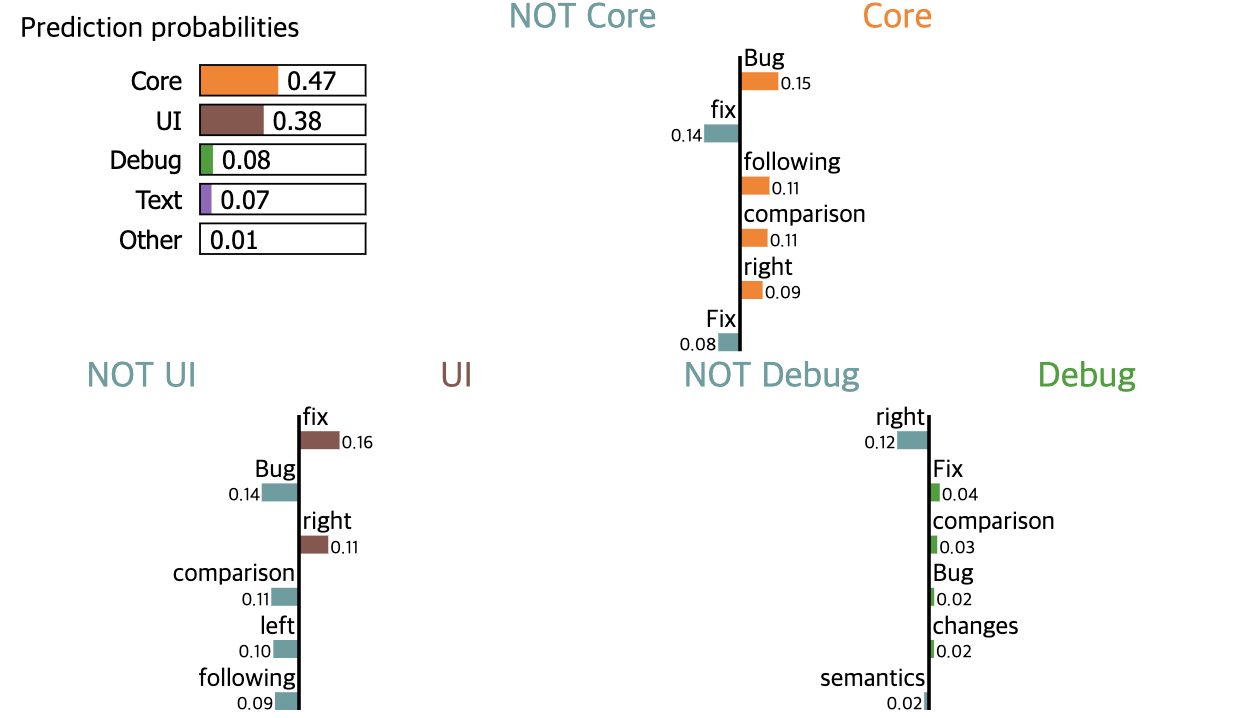
- submodular picks (하위 모듈 선택)
- 모델 성능을 전체적으로 해석하는데 도움이 되는 대표적인 샘플을 찾아줌
- 특정 샘플에 긍/부정 단어를 하이라이트 표시해서 보기 편함
- sklearn 선형 SVM에서는 작동하지만 복잡한 커널에서는 작동하지 않음
from lime import submodular_pick
import numpy as np
np.random.seed(42)
lsm = submodular_pick.SubmodularPick(explainer, er["text"].values, pipeline.predict_proba,
sample_size=100,
num_features=20,
num_exps_desired=5) # 로컬에서 7분 정도 걸림
lsm.explanations[10].show_in_notebook() # sample_size개수만큼 만들어줌
ELI5
- Explain it to me like I’m 5
- 비선형 SVM에 사용할 수 있음
- LIME에 비해 더 적은 코드로 구현 가능
- LIME과 같이 예시(샘플)로만 설명이 가능한 단점이 존재함
- libsvm으로 훈련된 모델이 필요
- 긍정적인 단어는 녹색으로, 부정적인 단어는 적색으로 표시
- 색이 짙을 수록 클래스에 대한 단어의 기여도가 높다는 것을 의미
import eli5
eli5.show_weights(svm, top=10, vec=tfidf, target_names=class_names)
- 개별 관측 결과 시각화
eli5.show_prediction(svm, X_test.iloc[21], vec=tfidf, target_names=class_names)
Anchor
- LIME과 같이 모델에 구애받지 않고 독립적으로 작동
- 모델의 동작을 설명하는 ‘앵커’라는 규칙을 만듦
- 규칙으로 모델의 예측을 설명하고 모델이 학습한 것과 같은 방식으로 예측 가능
- LIME 대비 규칙으로 모델을 더 잘 설명한다는 이점이 있음
마스킹된 단어 분포 사용 예시
- 예측에 중요하지 않은 기존 토큰을 unknown으로 대체하여 모델이 어떻게 결정을 내리는지 설명
- UNK 토큰은 특정 샘플에서 중요하지 않아도 알고리즘 결정에 영향을 미치는 실제적인 단어로 대체될 수 있음
# ! pip install anchor-exp
import spacy
from anchor import anchor_text
import time
import numpy as np
np.random.seed(42)
nlp = spacy.load('en_core_web_lg')
explainer_unk = anchor_text.AnchorText(nlp, class_names, use_unk_distribution=True)
exp_unk = explainer_unk.explain_instance(text, pipeline.predict, threshold=0.95)
print(f'Rule: {" AND ".join(exp_unk.names())}') # Rule: following AND comparison AND Bug AND semantics AND for
print(f'Precision: {exp_unk.precision()}') # Precision: 0.9736070381231672
print(f'Made-up examples where anchor rule matches and model predicts {pred}\n') # Made-up examples where anchor rule matches and model predicts Core
print('\n'.join([x[0] for x in exp_unk.examples(only_same_prediction=True)]))
실제 단어 사용
- use_unk_distribution=False: 앵커에 실제 단어를 사용하도록 지시 및 모델 동작을 관찰 가능
- spacy의 단어 벡터를 사용해 대체하는 것과 유사함
- 앵커는 일부 단어의 수정 사항에 대해 안정적임
- 예측 결과 예시
np.random.seed(42)
explainer_no_unk = anchor_text.AnchorText(nlp, class_names, use_unk_distribution=False)
exp_no_unk = explainer_no_unk.explain_instance(text, pipeline.predict, threshold=0.95)
print('Anchor: %s' % (' AND '.join(exp_no_unk.names())))
# Rule: following AND Bug AND comparison AND semantics AND left AND right
print('Precision: %.2f' % exp_no_unk.precision()) # 0.96
print('Examples where anchor applies and model predicts %s:' % pred)
print('\n'.join([x[0] for x in exp_no_unk.examples(only_same_prediction=True)]))
- 중요한 단어 하이라이트 및 결과 표시
def predict_numerical(text):
res = pipeline.predict(text)
n = np.array([str(class_names.index(r)) for r in res])
return n
explainer_num = anchor_text.AnchorText(nlp, list(range(6)), use_unk_distribution=False)
exp_num = explainer_num.explain_instance(text, predict_numerical, threshold=0.95)
exp_num.show_in_notebook()
- 주의 사항
- 규칙만으로는 올바른 범주를 결정하기 어려움
- 말뭉치로 훈련할 때 모델이 매우 취약해보임
- 분류기가 작동한다는 사실을 발견했다고 분류기가 실제로 투명한 방식으로 학습했다는 의미는 아님
- 규칙만으로는 올바른 범주를 결정하기 어려움
Reference
반응형
'NLP' 카테고리의 다른 글
| Chapter 8. 비지도 학습: 토픽 모델링 및 클러스터링 (0) | 2023.09.30 |
|---|---|
| Chapter 6. 텍스트 분류 알고리즘 (0) | 2023.03.26 |
| Chapter 5. 특성 엔지니어링 및 구문 유사성 (0) | 2023.03.26 |
| Chapter 4. 통계 및 머신러닝을 위한 텍스트 데이터 준비 (0) | 2023.03.26 |
| Chapter 3. 웹사이트 스크래핑 및 데이터 추출 (0) | 2023.03.26 |




댓글