론 코하비, 다이앤 탕, 야 쉬, 『A/B 테스트 신뢰할 수 있는 온라인 종합 대조 실험』, 이기홍, 김기영, 에이콘출판사-MANNING(2022), p260-341.
17. The Statistics behind Online Controlled Experiments
Two-Sample t-Test
- \(H_0: mean(Y^t) = mean(Y^c)\)
- \(H_A: mean(Y^t) \ne mean(Y^c)\)
- t-statistic, \(T\)
- \(T = \displaystyle{\Delta\over \sqrt{var(\Delta)}}\)
- \(\Delta\): unbiased estimator
- difference between the Treatment average and the Control average
- \(var(\Delta) = var(\overline{Y^t} - \overline{Y^c}) = var(\overline{Y^t}) + var(\overline{Y^c})\)
- \(T\)가 클수록 귀무가설을 기각할 가능성이 높음
- p-value
- probability of observing the delta, or a more extreme delta
- 수집된 데이터를 기반으로 귀무가설이 참인지 여부(posterior probability)를 알려면 p-value와 likelihood가 필요함
- 신뢰구간이 0과 겹치는지 확인하는 것으로 델타가 통계적으로 유의한지 확인할 수 있다.
Normality Assumption
- 대부분 t-statistic에서 \(T\)가 정규 분포를 따른다는 가정하게 p-value를 계산함
- 평균 0, 분산 1
- 확인하려는 지표 \(Y\)의 표본 분포는 정규 분포를 따르지 않을 수 있음
- 표본의 크기가 증가할 때, 표본 평균 \(\overline{Y}\)는 중심 극한 정리에 따라 정규 분포를 따름
- 표본 분포의 왜도(skewness) → 표본 평균 \(\overline{Y}\)가 정규 분포를 갖기 위한 최소 표본 수 확인
- \(s = \displaystyle{E[Y-E(Y)]^3\over [Var(Y)]^{3/2}}\)
- 왜도가 작은 경우, 분포의 형태가 정규 분포에 가깝기 때문에 더 적은 수의 표본이 필요함
- 왜도를 줄이는 효과적인 방법: 지표를 변경하거나 값을 제한 (e.g. Revenue/User를 주당 $10로 제한)
- 표본 크기가 정규성 가정에 부합할 정도인지 확인하는 방법
- offline simulation 활용
- 표본을 무작위로 섞어 귀무가설 분포를 생성
- 통계 테스트를 활용하여 분포를 정규 곡선과 비교
- Kolmogorov–Smirnov
- Anderson-Darling
- Type I error rate이 사전 설정한 임계값(e.g. 0.05)에 제한되는지 확인
- 정규성 가정이 맞지 않다면, permutation test을 수행하여 귀무가설 분포에 대한 관측치 위치를 확인
- 표본 크기가 작을 때 활용
- offline simulation 활용
Type I/II Errors and Power
- Type I error: 실제로 차이가 없는데 차이가 있다고 결론
- conclude significant difference between Treatment and Control when there is no real difference
- Type II error: 실제로 차이가 있는데 차이가 없다고 결론
- conclude no significant difference when there really is one
- Type I error, Type II error는 tradeoff
- Type II error는 power (검정력)로 알려짐
- power = 1 - Type II error
- \(Power_{\delta} = P(|T|\ge1.96|true\;diff\;is\;\delta)\)
- power: 실제로 차이가 있을 때, 변수 사이의 차이를 감지할 가능성 (귀무가설 기각할 확률)
- 업계 표준은 테스트에서 80% 이상의 검정력을 달성하는 것
- 80% 검정력을 달성하는데 필요한 총 표본 수: \(n \approx \displaystyle{16\sigma^2\over \delta^2}\)
- \(\delta\): 실험군과 대조군의 차이
- 실험을 시행해야 알 수 있음
- power = 1 - Type II error
- 온라인 실험의 경우, 사용자가 오랜 기간에 걸쳐 방문하기 때문에 표본 크기 추정이 더 복잡함
- 실험 기간이 실제 표본 크기에 중요한 역할을 함
- 랜덤화 단위에 따라 표본 분산도 시간에 따라 변할 수 있음
- 트리거 조건이 실험에 따라 바뀌기 때문에, 표본 분산과 델타값이 변함 → 트래픽 할 당 및 기간 설정이 중요
- 표본 크기가 작은 경우
- 추정이 잘못된 방향에 있을 확률을 계산 (Type S [sign] error)
- 효과의 중요도가 과대 평가될 수 있는 요인을 계산 (Type M [magnitude] error)
Multiple Testing
- 지표들이 독립적이라면, 변수가 아무 효과가 없어도 통계적으로 유의한 지표의 수는 유의 수준과 동일한 비율이다.
- e.g. 100개 지표, 5% 유의 수준 → 5개가 통계적으로 유의함
- 여러 실험을 병렬로 테스트할 때, false discoveries가 증가함 → Multiple testing 문제
- Multiple testing에서 Type I, Type II error를 통제하는 방법: 베이지안 해석 활용
- 모든 지표를 3가지 그룹으로 분리
- 1차 지표: 실험에 영향을 받을 것으로 예상되는 지표
- 2차 지표: 잠재적으로 영향을 받을 수 있는 지표
- 3차 지표: 영향받지 않는 지표
- 각 그룹에 계층별 유의 수준을 적용 (e.g. 0.05, 0.01, 0.001)
- 모든 지표를 3가지 그룹으로 분리
Fisher’s Meta-analysis
- 동일한 가설에 대한 여러 테스트 결과를 결합하는 방법
- 검정력을 높이고 false-positives을 줄이는데 유용함
- \(X^2_{2k} = -2\displaystyle\sum^k_{i=1}{ln(p_i)}\)
- \(p_i\): i번째 가설 검정의 p-value
- 모든 k개의 귀무가설이 참이면, 검정 통계량은 2k 자유도의 chi-squared distribution을 따름
18. Variance Estimation and Improved Sensitivity: Pitfalls and Solutions
- 분산은 p-value와 신뢰구간 계산에서 가장 중요한 요소
- 분산을 계산하기 위한 일반적인 절차 (i.i.d.)
- 지표를 계산: \(\overline{Y} = \displaystyle{1\over n}\sum^n_{i=1}Y_i\)
- 표본 분산을 계산: \(var(Y) = \sigma^2 = \displaystyle{1\over n-1}\sum^n_{i=1}{(Y_i-\overline{Y})^2}\)
- 지표 평균의 분산을 계산: \(var(\overline{Y}) = var\Big(\displaystyle{1\over n}\sum^n_{i=1}{Y_i}\Big) = {1\over n^2}*n*var(Y) = {\hat{\sigma}^2\over n}\)
Common Pitfalls
- 분산을 잘못 추정하면 p-value와 신뢰구간이 잘못되어 가설 검정의 결론에 오류가 발생함
- 분산을 실제보다 크게 추정: false negative
- 분산을 실제보다 작게 추정: false positive
- Delta vs. Delta %
- 실험 결과 보고 시, 상대적 차이(percent delta)를 사용하는 것이 일반적
- 세션이 평균보다 0.01개 많은 것보다 1% 증가한 것이 더 이해하기 쉬움
- percent delta: \(\Delta \% = \displaystyle{\Delta \over \overline{Y^c}}\)
- percent delta의 신뢰구간을 올바르게 추정하려면 분산을 추정해야 함
- 일반적으로 \(var(\Delta)\)를 \(\displaystyle{var(\Delta)\over \overline{Y^c}^2}\)로 추정하는 실수를 함
- 올바른 추정 방법: \(var(\Delta \%) = \displaystyle var\Big({\overline{Y^t} - \overline{Y^c} \over \overline{Y^c}}\Big) = var\Big({\overline{Y^t}\over \overline{Y^c}}\Big)\)
- 실험 결과 보고 시, 상대적 차이(percent delta)를 사용하는 것이 일반적
- Ratio Metrics. When Analysis Unit Is Different from Experiment Unit
- 많은 중요 지표들은 두 지표의 비율에서 비롯됨
- e.g. CTR = total clicks / total pageviews
- 실험이 사용자 단위로 랜덤화되면 분산 추정에 어려움이 생길 수 있음
- 분산 공식에서는 i.i.d (독립적으로 동일하게 분포) or 서로 상관관계가 없다는 중요한 가정이 근간
- 분석 단위가 실험 랜덤화 단위와 동일하면 가정이 충족됨
- 분산을 정확하게 추정하기 위해 단위를 통일해야 함
- e.g. 실험이 사용자에 의해 랜덤화되고 페이지 수준의 지표를 보고 싶은 경우
- 비율 지표를 사용자 수준 지표의 평균의 비율로 작성 가능
- 사용자별 비율 지표를 계산하고 이 값을 실험군 내에서 평균
- \(M = \displaystyle{\overline{X}\over \overline{Y}}\)
- 델타 방법으로 분산 추정
- \(var(M) = \displaystyle{1\over \overline{Y}^2}var(\overline{X}) + {X^2\over \overline{Y}^4}var(\overline{Y}) - 2{\overline{X}\over \overline{Y}^3}cov(\overline{X}, \overline{Y})\)
- \(var(\Delta \%) = \displaystyle{1\over \overline{Y}^{c^2}}var(\overline{Y^t}) + {\overline{Y^{t^2}}\over \overline{Y}^{c^4}}var(\overline{Y^c})\)
- 사용자 수준의 비율 지표로 기록할 수 없는 경우 → 대체하는 샘플링 방식으로 랜덤화하여 bootstrap 방법을 활용
- 비율 지표를 사용자 수준 지표의 평균의 비율로 작성 가능
- 많은 중요 지표들은 두 지표의 비율에서 비롯됨
- Outliers
- 이상치의 상대적 크기가 증가하면 t-statistic이 감소하고 검정이 통계적으로 유의하지 않음 → 제거 필요
- 실용적인 방법: 합리적인 임계값 이하의 값으로 관측값을 제한 (e.g. 사용자 daily 페이지뷰 500번 이하로 제한)
Improving Sensitivity
- power or sensitivity: 실험 효과를 감지하는 능력
- sensitivity를 향상하는 방법: 분산을 줄이기
- 더 적은 분산을 가진 평가 지표를 만들기 (e.g. 구매 금액 → 구매 여부)
- 값을 제한하거나(capping) binarization, 로그 변환을 통해 지표를 변환
- 해석력이 중요하지 않을 경우 로그 변환을 고려
- 트리거 분석을 활용
- 변수의 영향을 받지 않는 사람들에 의해 발생하는 노이즈를 제거하는 방법
- stratification, Control-variates, CUPED 활용
- stratification (e.g. platform, browser type)
- 샘플링 영역을 계층으로 나누고,
- 각 층 내에서 개별적으로 샘플을 수집한 다음
- 전체 추정치에 대해 개별 층의 결과를 결합하는 것
- Control-variates
- 공변량을 회귀 변수로 사용하여 다중회귀분석을 시행
- 공변량에 의한 편향을 측정한 후, 제거하는 방법
- CUPED: Controlled Experiments by Utilizing Pre-Experiment Data
- 온라인 실험에서 사전 실험 데이터를 통제 변수로 활용하는 방법
- stratification (e.g. platform, browser type)
- 더 세분화된 단위로 랜덤화
- 사용자 경험에 나쁜 영향을 줄 수 있음
- paired experiment을 설계
- e.g. interleaving 설계: 랭킹 방식을 평가하는 일반적인 방법
- 두 순위 목록을 교차배포하고 사용자에게 합쳐진 목록을 제공
- e.g. interleaving 설계: 랭킹 방식을 평가하는 일반적인 방법
- Control group을 통합
- 각 실험마다 고유한 트리거 조건이 있는 경우, 동일한 대조군을 사용하기 어려울 수 있음
- 실험군끼리 직접적으로 비교하고 싶을 수 있음
Variance of Other Statistics
- PLT(page load time)와 같은 시간 기반 지표의 경우, 분위수를 사용하는 것이 일반적
- 이벤트/페이지 수준의 시간 기반 지표의 실험은 사용자 수준에서 랜덤화됨 → 밀도 추정 + 델타 방법의 조합을 적용
19. The A/A Test
- A/A 테스트
- 개념: 사용자를 두 그룹으로 나누지만 B를 A와 동일하게 만듦
- 반복 시행에서 약 5% 경우에 지표는 0.05 미만의 p-value를 지니며 통계적으로 유의해야 함
- p-value를 계산하기 위해 t-test를 수행할 때, 반복 시행에서 얻은 p-value의 분포는 균등 분포에 가까워야 함
- 실험 플랫폼에 대한 신뢰를 구축 가능
- 현실에서 테스트가 실패하는 것을 발견할 수 있고, 이에 따라 가정을 재평가하고 오류 식별 가능
- 개념: 사용자를 두 그룹으로 나누지만 B를 A와 동일하게 만듦
Why A/A Tests?
- Type I error가 예상대로 통제되는지 확인
- 표준 분산 계산에서 일부 지표에 대해 올바르지 않거나, 정규성 가정이 유지되지 않을 수 있음
- 지표의 변동성을 평가
- 시간에 따른 지표 분산의 변화를 확인 가능
- 이전 실험의 모집단을 재사용하는 경우, 실험군과 대조군의 사용자 간에 편향이 없는지 확인
- 플랫폼 수준에서 편향을 식별하는데 효과적인 방법
- e.g. Bing은 연속 A/A 테스트를 사용하여 carry-over effect(이월 효과)를 식별함
- 시스템의 기록과 데이터를 비교
- A/A 테스트는 조직에서 종합 대조 실험을 사용하기 전에 첫 번째 단계로 사용됨
- 주요 지표(e.g. CTR)가 시스템 기록과 일치하는지 확인
- 실험 세팅대로 이행이 되었는지 확인
- 웹사이트를 방문한 X명의 사용자 중, 실험군과 대조군에 20%씩 할당한 값이 그대로 되었는지 검증
- 통계적 검정력 계산을 위한 분산 추정
- A/A 테스트를 통해 최소한의 감지가 가능한 효과를 얻기 위해 A/B 테스트를 얼마나 실행해야 하는지 결정하는데 필요한 지표의 분산을 제공함
Example
- Analysis Unit Differs from Randomization Unit
- e.g. 사용자별로 랜덤화하고 페이지별 분석하는 것이 필요한 실험
- CTR 계산 방식
- 모든 클릭 수를 계산하고 총 페이지 뷰 수로 나누는 방법
- \(CTR = \displaystyle{\sum^n_{i=1}\sum^{K_j}{j=1}X{i,j} \over N}\)
- \(N\): 총 페이지 뷰 수 (\(N = \sum^n_{i=1}K_i\))
- \(K_i\): 사용자 \(i\)의 페이지 뷰 수
- \(n\): 사용자 수
- \(X_{i,j}\): 사용자 \(i\)가 페이지 \(j\)를 클릭한 수
- 각 사용자의 CTR을 평균한 다음, 모든 CTR의 평균을 계산하는 방법
- \(CTR = \displaystyle{\sum^n_{i=1}{\sum^{K_j}{j=1}X{i,j} \over K_i}\over n}\)
- 이상치에 대해 덜 영향을 받으므로 권장하는 방법
- 모든 클릭 수를 계산하고 총 페이지 뷰 수로 나누는 방법
- 분산의 불편 추정치는 델타 방법 or bootstrapping을 사용하는 것을 권장
- Optimizely Encouraged Stopping When Results Were Statistically Significant
- 통계학에서는 일반적으로 실험의 마지막에 한 번의 테스트가 수행하는 것을 전제로 함
- 중간 과정에서 테스트를 수행하는 것(peeking)은 예상보다 많은 false-positive를 도출
- Optimizely 초기 버전은 중간 과정 테스트와 조기 종료를 장려하여 수많은 거짓된 개선을 야기했음
- “How Optimizely (Almost) Got Me Fired” 기사 참조
- 통계학에서는 일반적으로 실험의 마지막에 한 번의 테스트가 수행하는 것을 전제로 함
- Browser Redirects
- 웹사이트 새 버전을 구축 중이고 A/B 테스트를 실행한다고 했을 때, B(새 버전)는 높은 확률로 실패할 수 있음
- 실험군 B 사용자는 새로운 웹사이트로 리디렉션 되는 경우
- 일반적으로 리디렉션은 A/A 테스트에 실패함
- 리디렉션이 없도록 구성하거나 변형군 모두 리디렉션을 실행해야 함
- 원인
- 성능 차이
- 리디렉션 된 사용자는 추가적인 리디렉션을 겪음 → 1-2초의 대기 시간을 겪을 수 있음
- 봇
- 일부는 리디렉션 되지 않을 수 있음
- 대량의 크롤링을 수행하여 주요 지표에 영향을 미칠 수 있음
- 북마크와 공유 링크는 오염을 유발함
- 북마크와 공유 링크를 통해 웹사이트로 이동하는 사용자는 계속 리디렉션 되어야 함
- 리디렉션은 변형군 간에 대칭이어야 하므로, 대조군 사용자도 리디렉션 되어야 함
- 성능 차이
- 웹사이트 새 버전을 구축 중이고 A/B 테스트를 실행한다고 했을 때, B(새 버전)는 높은 확률로 실패할 수 있음
- Unequal Percentages
- 균등하지 않게 분할한 경우, 리소스 분배가 더 큰 변형군에게 유리하게 적용될 수 있음
- 대조군과 실험군 간에 공유되는 LRU(Least Recently Used) 캐시는 큰 변형군에 더 큰 캐시 항목을 가지게 됨
- 정규 분포로의 수렴 속도가 다름
- 한쪽으로 과도하게 치우친 분포가 있다면, 중심극한정리는 백분율이 다르면 평균은 정규분포로 수렴하지만 수렴 속도가 달라짐을 보임
- 균등하지 않게 분할한 경우, 리소스 분배가 더 큰 변형군에게 유리하게 적용될 수 있음
- Hardware Differences
- 하드웨어(신형, 구형)의 차이로 예상치 못한 일이 발생할 수 있음
How to Run A/A Tests
- 이상적으로는 1,000개의 A/A 테스트를 시뮬레이션하고 p-value의 분포를 시각화하는 것이 좋음
- 분포가 균등하지 않다면 문제가 있는 것
- 델타 방법을 활용하는 것이 좋음
- 1,000번의 A/A 테스트를 실행하는 것은 비용이 많이 발생함
- 지난주의 실험을 반복하는 것으로 대체 가능
- 성능 문제를 포착하지 못하고 LRU 캐시와 같이 리소스를 공유하지 못하는 단점이 있음
- 많은 문제를 식별하는 데 도움을 줄 수 있는 장점이 있음
- 제품 변경이 필요 없음
- 지난주의 실험을 반복하는 것으로 대체 가능
- 적합도 테스트(Goodness of fit test)를 실행해서 분포가 균등에 가까운지 평가
- Anderson-Darling or Kolmogorov-Smirnoff 검정
When the A/A Test Fails
- p-value의 균등 분포에 대한 적합도 테스트가 실패하는 일반적인 시나리오
- 분포가 치우쳐 있고 명확하게 균등하지 않은 경우 → 분산 추정 문제
- 랜덤화 단위와 분석 단위가 달라서 독립성 가정이 위반됐을 수 있음 → 델타 방법, 부트스트래핑 활용
- 지표가 매우 치우쳐진 분포 → 제한된 지표 or 최소 표본 크기 설정으로 해결
- p-value가 0.32 주변에 몰려있는 경우 → 이상치 문제
- 이상치의 원인을 조사하거나 데이터를 제한해야 함
- 분포가 큰 간격으로 값이 몇 개의 점에 몰려있는 경우 → 대부분 단일 값을 가지고 몇 개의 0이 아닌 값을 가질 때 발생
- 새로운 실험이 희소한 사건을 더 빈번하게 발생시키므로 실험효과가 더 커지고 통계적으로 유의하게 될 수 있음
- 분포가 치우쳐 있고 명확하게 균등하지 않은 경우 → 분산 추정 문제
- A/A 테스트 통과 이후에도 A/B 테스트와 동시에 정기적으로 A/A 테스트를 실행해서 문제를 사전 대응하는 것을 권장
20. Triggering for Improved Sensitivity
- 트리거링: 실험의 영향을 받지 않았을 사용자가 생성한 노이즈를 필터링해서 민감도를 개선할 수 있는 방법
Examples of Triggering
- 변경의 영향을 받았을 가능성이 있는 사용자만 분석 → 민감도 or 통계적 검정력을 크게 향상할 수 있음
- Intentional Partial Exposure
- e.g. 특정 지역만 대상으로 분석을 해야 하는 경우
- treatment 대상이 실험 전의 데이터를 기반으로 명확하게 정의되어야 함
- treatment에 의해서 정의 자체가 영향을 받지 않아야 함
- Conditional Exposure
- 사용자가 특정 조건을 만족하는 것 자체가 차이를 만들게 됨 → 변경 사항에 사용자가 노출되자마자 실험에 트리거 됨
- Coverage Increase
- e.g. 무료 배송 가격 조건을 변경하는 실험 ($35 → $25)
- $25~$35에 해당되는 사용자만 트리거링
- Coverage Change
- 적용 범위가 변경되는 경우는 확대보다 복잡함
- 변형군 모두 counterfactual을 평가하고, 두 변형 군 간에 차이가 있는 경우에만 사용자가 트리거 된 것으로 표시
- 실험군과 대조군의 각각의 차집합에 해당되는 부분을 의미
- Counterfactual Triggering for Machine Learning Models
- 새로운 ML 모델이 대부분 사용자에 대해 기존 ML 모델과 중복된다면 실험효과는 없음
- counterfactual을 생성해야 함
- 대조군에서 기존/신규 모델을 모두 실행하고 출력값을 로그에 기록
- 출력에 차이가 있는 사용자만 트리거
- 계산 비용이 증가하는 단점이 있음
- 모델이 병렬로 실행되지 않으면 지연시간도 영향을 받을 수 있음
- counterfactual을 생성해야 함
- 새로운 ML 모델이 대부분 사용자에 대해 기존 ML 모델과 중복된다면 실험효과는 없음
A Numerical Example
- 최소 표본 크기 산출
- \(n = \displaystyle {16\sigma^2\over \Delta^2}\)
- e.g. 방문한 사용자 중, 5%만 실제 구매를 하는 경우
- \(n=16*0.05(1-0.05)/(0.05\cdot 0.05)^2=121,600\)
- e.g. 사용자 10%가 결제를 시작하고 5%의 구매율이 주어진 경우
- 결제 완료 = 5%/10% = 50%
- \(n=16*0.5(1-0.5)/(0.5\cdot 0.05)^2=64,000\)
- 절반의 시간 내에 동일한 검정력을 가질 수 있음
Optimal and Conservative Triggering
- 최적의 트리거 조건: 변수 적용으로 인해, 차이가 발생한 사용자에게만 분석을 하는 것
- 다중 실험군의 경우, 모든 변형군에 대한 사실(actual plus)과 반사실(counterfactual)을 기록하는 것이 이상적임
- 상당히 많은 비용이 소모됨 → 반사실을 생성하기 위해 여러 모델을 실행해야 함
- 보수적인 트리거링: 최적보다 많은 사용자를 포함하는 것
- 통계적 검정력이 떨어질 수 있음
Overall Treatment Effect
- 트리거 된 모집단에 의한 실험 효과를 계산할 때, 반드시 효과를 전체 사용자 기반으로 희석해야 함
- e.g. 사용자 10%에 대해 수익이 3% 증가 → 전체 수익이 10% * 3% = 0.3% 증가한 것이 아님
- 심슨의 역설을 유발할 수 있음
- Formulation
- 기호
- \(w\): 전체 사용자
- \(\theta\): 트리거 된 사용자
- \(C\): 대조군
- \(T\): 실험군
- \(N\): 사용자 수
- 트리거된 모집단의 절대 효과: \(\Delta_{\theta} = M_{\theta T} - M_{\theta C}\)
- 트리거된 모집단의 상대 효과: \(\delta_{\theta} = \Delta_{\theta} / M_{\theta C}\)
- 트리거링 비율: \(\tau = N_{\theta C} / N_{wC}\)
- 실험군과 대조군을 결합한 비율: \((N_{\theta C} + N_{\theta T}) / (N_{wC} + N_{wT})\)
- 기호
- 희석된 백분율 효과를 다루는 방법
- 실험 효과를 전체로 나누는 경우
- \(\displaystyle{{\Delta_{\theta} * N_{\theta C}}\over M_{wC} * N_{wC}}\)
- 트리거 되지 않은 지표에 대한 실험 효과 비율과 트리거링 비율을 곱하는 경우
- 트리거 되지 않은 지표에 대한 실험 효과 비율: 10% 사용자에 대해 3% 수익 개선이 있는 경우 전체 수익이 10%*3% = 0.3% 개선된다는 것을 의미
- \(\displaystyle{\Delta_{\theta}\over M_{wC}} * \tau\)
- 실험 효과를 전체로 나누는 경우
Trustworthy Triggering
- 신뢰할 수 있는 트리거링을 위해 2가지 검사가 필요
- SRM (Sample Ratio Mismatch)
- 전체 실험에 SRM이 없지만, 트리거된 분석이 SRM을 보여준다면 약간의 편향이 도입된 것
- 반사실 트리거링이 제대로 수행되지 않았을 경우 주로 나타남
- Complement analysis
- 한 번도 트리거 되지 않은 사용자에 대한 점수를 생성하고 A/A 테스트 점수를 구해서 확인
- 예상한 지표보다 통계적으로 유의미한 경우, 트리거 조건이 올바르지 않을 가능성이 높음
Common Pitfalls
- Experimenting on tiny segments that are hard to generalize
- Amdahl’s law: 전체 실행 시간의 작은 부분을 차지하는 시스템 일부분의 속도를 높이는 것을 피하기 위해 언급됨
- A triggered user is not properly triggered for the remaining experiment duration
- Performance impact of counterfactual logging
- A/A’/B 실험을 실행
- A: original system (대조군)
- A’: 반사실 기록이 있는 original system
- B: 반사실 로깅이 있는 새 실험군
- A, A’이 크게 다를 경우, 반사실의 로그가 영향을 받고 있다는 경고가 됨
- A/A’/B 실험을 실행
- Open questions
- Triggering unit: 어느 시점에서 진행하는 것이 좋을까?
- 계산상으로는 사용자가 트리거 되는 경우, 실험 시작부터의 데이터를 갖고 고려하는 것이 쉽지만, 통계적 검정력이 약간 손실됨
- Plotting metrics over time
- 매일 그날 방문한 사용자를 보여주는 그래프를 시간 경과에 따라 살펴보는 것이 가장 좋음
- 당일 방문해서 트리거 된 사용자로 매일 시각화하는 것이 좋음
- 첫째 날 트리거된 일부 사용자가 방문을 둘째 날에 할 수 있기 때문
- Triggering unit: 어느 시점에서 진행하는 것이 좋을까?
21. Sample Ratio Mismatch and Other Trust-Related Guardrail Metrics
- Guardrail Metrics: 가정이 위반될 경우 실험자에게 경고하기 위해 설계된 지표
- 조직 관련 지표와 신뢰 관련 주표가 있음
- SRM(Sample Ratio Mismatch): 신뢰 관련 가드레일 지표
Sample Ratio Mismatch
- 일반적으로 실험군, 대조군과 같은 두 변형군 사이의 사용자 비율을 확인
- SRM에서 실험 설계 시, p-value가 낮은 경우 SRM이 있고 다른 모든 지표도 유효하지 않을 수 있음
- 표준 t-test or chi-squared test로 계산 가능
- 발생 원인
- Buggy randomization of users
- Data pipeline issues
- Residual effects
- Bad trigger condition
- Triggering based on attributes impacted by the experiment
Debugging SRMs
- Sample Ratio guardrail metric에 대한 p-value가 낮다면, 시스템 어딘가에 버그가 있다고 가정해야 함
- common directions
- 랜덤화 시점 or 트리거 시점 이전 단계에 차이가 없는지 검증
- 실험군, 대조군 할당이 올바른지 검증
- 데이터 처리 파이프라인의 단계별 SRM의 원인이 있는지 확인
- 실험 시작 후, 초기 기간을 제외
- 세그먼트의 샘플 비율을 확인
- 다른 실험과의 공통점을 확인
Other Trust-Related Guardrail Metrics
- Telemetry fidelity
- Cache hit rates
- Cookie write rate
22. Leakage and Interference between Variants
- Rubin causal model
- 종합 대조 실험을 분석하기 위한 표준 프레임워크
- SUTVA(stable unit treatment value assumption)를 가정함
- 각 실험단위의 행동은 다른 실험단위에 대한 변형군 할당에 의해 영향을 받지 않는다는 것
- interference: SUTVA 가정을 위반한 것
- 실험 간 spillover or leakage로도 불림
- direct or indirect 연결로 interference가 발생할 수 있음
- direct: SNS 상에서 친구 거나 동시에 동일한 물리적 공간을 방문한 경우
- indirect: 잠재 변수 or 공유 리소스로 인해 생기는 연결
- 실험군과 대조군을 연결하고 상호작용하는 중간 매개체가 있다는 공통점이 있음
Direct Connections
- 직접 연결된 두 단위는 실험군과 대조군으로 분리되어 실험 간의 간섭을 유발할 수 있음
- SNS에서 사용자의 행동은 이웃의 행동에 영향을 받을 가능성이 있음
- 더 많은 이웃이 특정 기능을 사용할수록 사용자는 그 기능을 사용하려고 함
- A/B test에서 실험군이 사용자에게 상당한 영향을 미치는 경우 효과가 점진적으로 퍼질 수 있음
- B(신규) 안에 대한 이점을 완전히 포착하지 못할 수 있음
Indirect Connections
- 직접 연결과 마찬가지로 간섭을 유발하거나 변수 적용 효과의 편향된 결론을 야기할 수 있음
- 사례
- Airbnb: 실험군 사용자의 구매 전환 흐름 개선
- 더 많은 예약을 실험군에게 유도하면 대조군 사용자의 재고가 줄어듦 → 대조군 발생 수익이 적어짐 ⇒ 실험효과가 과대 평가됨
- Uber/Lyft: 할증 요금 알고리즘 테스트
- 알고리즘의 반응이 좋아서 실험군 고객들이 더 많이 이용 → 운전자 적어짐 → 대조군 가격이 올라감 ⇒ 델타가 과대 평가됨
- eBay: 구매자의 할인 or 판촉과 같은 입찰 장려
- 변경군은 동일한 아이템에 대해 경쟁
- 실험군의 입찰가격이 높을수록 대조군 사용자의 경매 승산율이 낮아짐 ⇒ 총 거래수가 지표라면 델타는 과대 평가됨
- Airbnb: 실험군 사용자의 구매 전환 흐름 개선
Some Practical Solutions
- Rule-of-Thumb: Ecosystem Value of an Action
- 다운스트림 영향을 나타낼 수 있는 지표를 활용
- e.g. 작성된 총 게시물 수 및 받은 총 좋아요/댓글 수
- 1차 행동으로 인한 잠재적으로 생태계 내에 미치는 영향의 깊이와 폭을 추정할 수 있음
- 각 행동이 전체 생태계에 대한 가치 또는 참여로 어떻게 변환되는지에 대한 일반적인 지침을 설정할 수 있음
- 다운스트림 영향이 있다고 입증된 과거 실험을 사용하여, 영향을 도구 변수 방법을 사용하여 사용자 행동 X/Y/Z의 다운스트림 영향에 외삽하는 것으로 추정 가능
- 생태계 가치를 한 번만 구축하면 됨
- 베르누이 무작위 실험에도 적용 가능
- 모든 시나리오에 작동하지 않을 수 있는 단점이 존재
- 다운스트림 영향을 나타낼 수 있는 지표를 활용
- Isolation
- 실험군과 대조군을 연결하는 매개체를 격리시켜서 잠재적인 간섭을 제거 가능
- 방법
- Splitting shared resources
- Geo-based randomization
- Time-based randomization
- Network-cluster randomization
- Network ego-centric randomization
- 가능하다면 격리 방법을 결합하여 더 큰 표본 크기를 얻는 것이 좋음
23. Measuring Long-Term Treatment Effects
What Are Long-Term Effects?
- 단기 효과: 짧은 기간에 측정된 실험 효과
- 대부분의 실험에서 단기 효과는 안정적임
- 장기 실험 효과로 일반화될 수 있음
- 때로는 장기 효과와 단기 효과가 다른 시나리오가 존재할 수 있음
- e.g. 가격을 올리기 → 단기 수익은 증가, 장기 수익은 감소
- 장기 효과: 몇 년 후에도 지속될 수 있는 실험의 점근적 효과
- 3개월 이상, 노출 횟수(e.g. 10회 이상 노출된 사용자)를 기준으로 정하는 것이 일반적임
Reasons the Treatment Effect May Differ between Short-Term and Long-Term
- User-learned effects
- Network effects
- Delayed experience and measurement
- Ecosystem change
- Launching other new features
- Seasonality
- Competitive landscape
- Government policies
- Concept drift
- Software rot
Why Measure Long-Term Effects?
- Attribution: 새로운 기능을 도입하기 전후 어떤 모습일지 확인 가능
- Institutional learning
- Generalization
Long-Running Experiments
- 장기 효과를 측정하는 일반적인 접근법 → 실험을 장기간 실행하는 것
- 실험 시작과 종료에 실험 효과를 측정할 수 있음
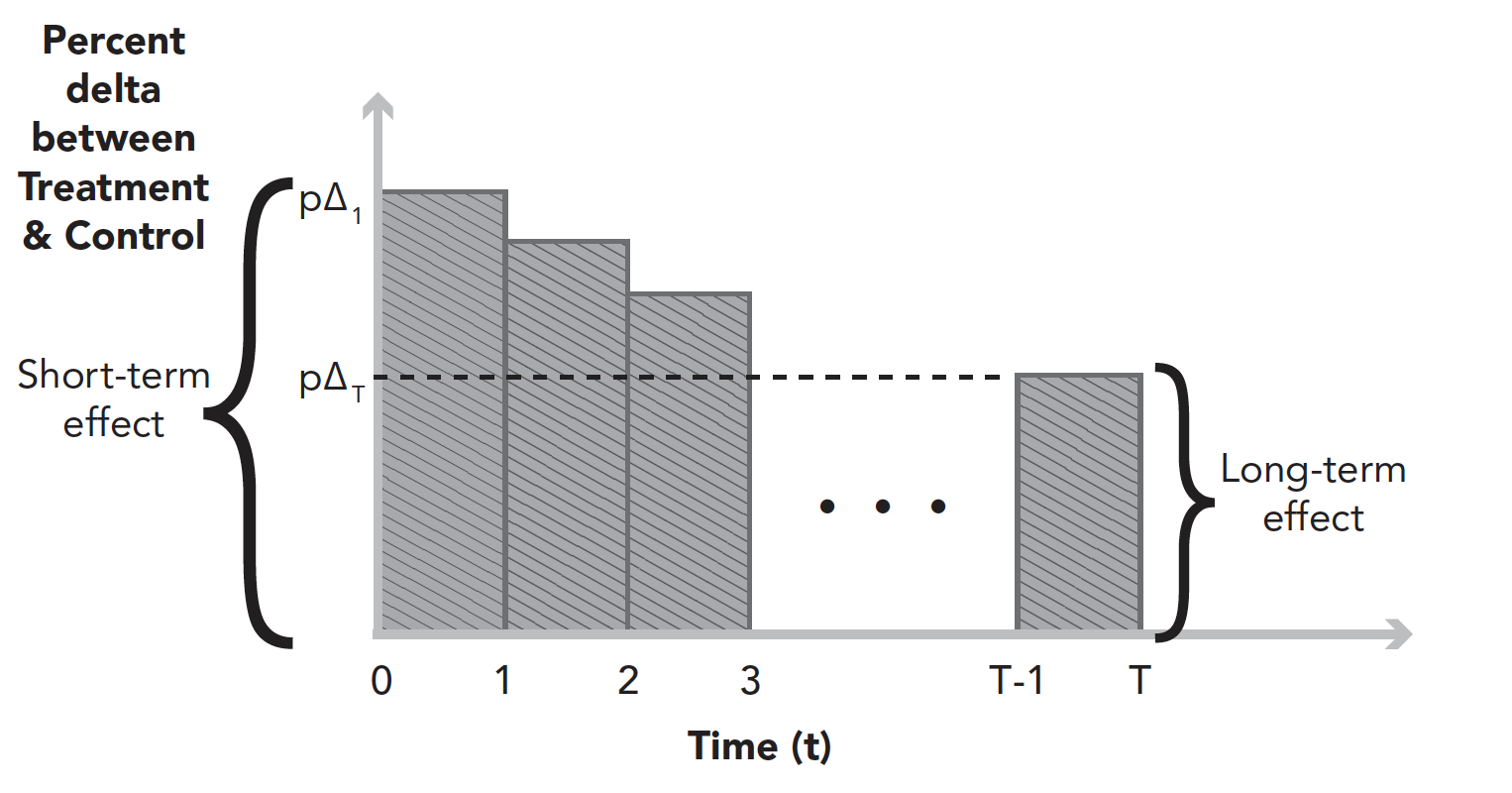
Long-Running Experiments
- 장기 효과를 측정하는 일반적인 접근법 → 실험을 장기간 실행하는 것
- 실험 시작과 종료에 실험 효과를 측정할 수 있음
- attribution: 장기 실험의 종료 시점의 측정값은 장기 실험 효과를 나타내지 않을 수 있음
- 실험 효과 희석(dilution)
- 사용자의 사용 기기 or 진입 방법 증가
- 쿠키 기반 실험 단위 선정 시, 쿠키가 삭제되거나 브라우저 문제로 인해 방해받을 수 있음
- 네트워크 효과가 있는 경우, 변형군 간에 완벽한 격리가 없으면 실험효과가 실험군에서 대조군으로 유출될 수 있음
- Survivorship bias
- 변형군 간에 생존율이 다른 경우 SRM을 유발할 수 있음
- Interaction with other new features
- 새로운 기능은 시간이 지남에 따라 실험의 성과를 떨어뜨릴 수 있음
- For measuring a time-extrapolated effect(외삽 효과)
Alternative Methods for Long-Running Experiments
- Cohort Analysis
- 안정적인 식별장치에 기반한 코호트 이용 (ex. 로그인한 사용자 ID)
- 코호트가 전체 모집단을 대표하는지 외적 타당성 문제 검증
- 계층화를 기반으로 한, 가중치 조정과 같은 추가적인 방법을 사용하여 일반화 성능을 개선 가능
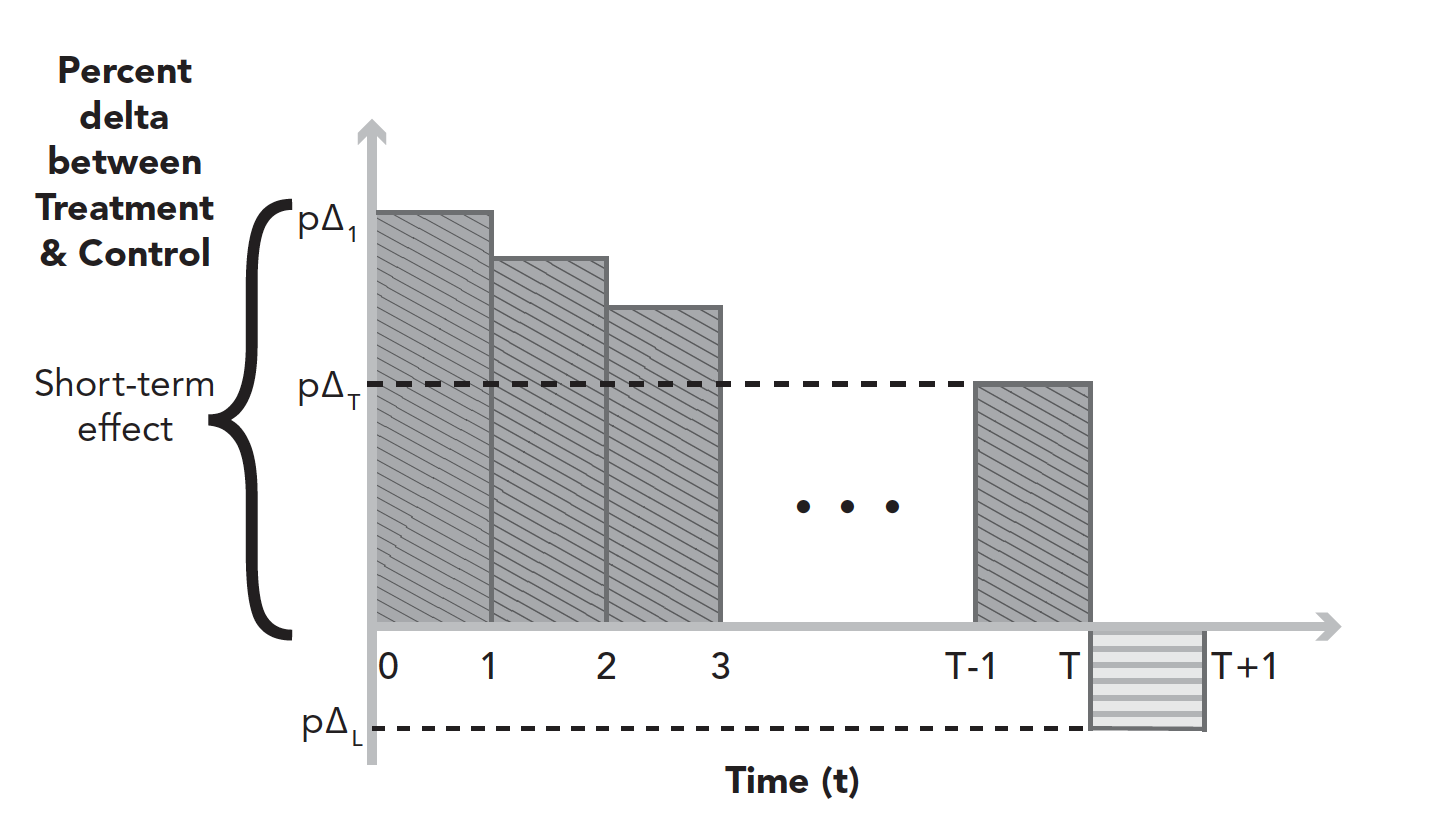
- Post-Period Analysis
- 실험을 한동안 실행한 후, 실행을 중지하고 T~T+1 시간 동안 실험군 사용자와 대조군 사용자 간의 차이를 계산
- 측정 기간 동안 변형군 사용자 모두 정확히 동일한 기능에 노출되었는지가 중요
- 그룹 간에 차이가 발생하는 이유
- 실험군이 대조군이 노출되지 않은 기능 세트에 노출되는 경우
- ramping up case: 실험군이 대조군보다 더 오랜 시간 동안 기능에 노출된 경우
- learning effect: effect measured during the post-period
- User-learned effect
- System-learned effect
- 학습된 효과를 시스템 파라미터 기반으로 추정한 다음, 새로운 단기 실험으로부터 장기 효과를 추정할 수 있음
- 실험군, 대조군 사용자가 같은 기능 세트에 노출되는 A/A 사후 기간과 같이 시스템 학습 효과가 없을 때 합리적임
- 시간이 지남에 따라 변경되는 외부 요인과 새로 출시된 다른 기능과의 잠재적 상호작용과 같은 영향을 격리하는데 효과적임
- 학습효과를 개별적으로 측정할 수 있으므로, 단기효과와 장기효과가 다른 이유에 대해서 더 많은 통찰력을 제공함
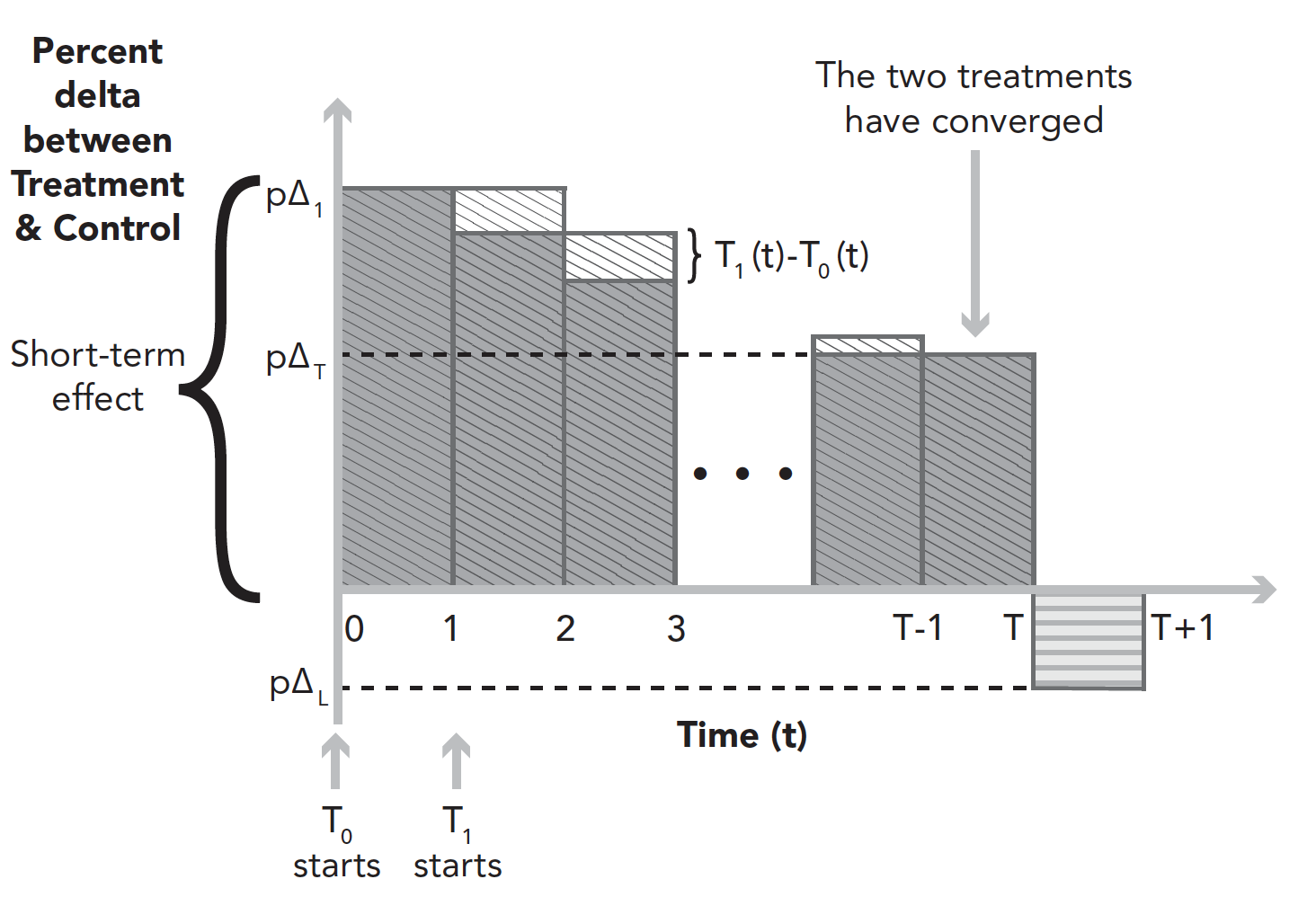
- Time-Staggered Treatments
- 측정 시간을 정하기 위해 동일한 실험군에 시차를 둔 두 가지 실험을 수행할 수 있음
- \(T_0\): t=0에서 시작
- \(T_1\): t=1에서 시작
- 실험에 노출되는 기간 차이만 제외하면 A/A test와 동일
- \(T_1(t)\)와 \(T_0(t)\)의 차이가 통계적으로 유의한지 확인 → two-sample t-test
- 장기 효과를 측정하기 위해 시간 t이후 사후 분석을 적용할 수 있음
- 측정 시간을 정하기 위해 동일한 실험군에 시차를 둔 두 가지 실험을 수행할 수 있음
- Holdback and Reverse Experiment
- 모든 사용자에게 실험을 시작해야 하는 시간적 압박이 있을 때 대안
- Holdback, Reverse Experiment
- holdback: 90% 사용자에 대해 실험한 후 몇 주(or 몇 달) 동안 사용자의 10%를 대조군으로 유지하는 방법
- 장기 실험의 전형적인 형태
- 대조군의 표본 크기가 작기 때문에 최적의 경보다 적은 검정력을 갖는 경향이 있음
- Reverse Experiment: 사용자의 100%로 실험군을 런칭한 몇 주(or 몇 달) 후 10%의 사용자를 대조군으로 다시 변경
- 모든 사람이 한동안 실험 효과를 받았다는 장점이 있음
- 네트워크 효과가 중요하거나 시장에서 공급이 제한되는 경우, 새로운 균형에 도달할 수 있는 시간을 줌
- 실험군에서 눈에 띄는 변화가 관찰되는 중에, 사용자를 다시 대조군으로 변경하면 혼란스러운 단점이 있음
- 모든 사용자에게 실험을 시작해야 하는 시간적 압박이 있을 때 대안
반응형
'Causal inference' 카테고리의 다른 글
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 5 (0) | 2023.10.16 |
|---|---|
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 18 (0) | 2023.10.15 |
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 17 (0) | 2023.10.12 |
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 12 (1) | 2023.10.11 |
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 16 (0) | 2023.10.11 |




댓글