반응형
인과추론의 데이터과학. (2021, Nov 1). [Session 14-1] 신약 개발에서의 인과추론의 역할과 한계 [Video]. YouTube.
인과추론의 데이터과학. (2021, Nov 1). [Session 14-2] 머신러닝을 활용한 이질적 인과관계 분석 [Video]. YouTube.
Session 14-1
약물 개발
- 신규
- 10-17년, $2-3 billion
- 높은 실패율 (평균적으로 90%)
- Recycling: repurposing
- 3-12년
- 안정성 담보
RCTs란? (Randomized clinical trials)
- treatment의 효과를 측정하는 방식
- 참가자들을 2가지 그룹으로 분리 (new treatment vs standard treatment)
- 비싸고, 높은 실패율, 때로는 안전하지 않음
- Emulated RCT의 경우 집단이 동일하지 않기 때문에, selection bias가 존재함

Potential outcome framework

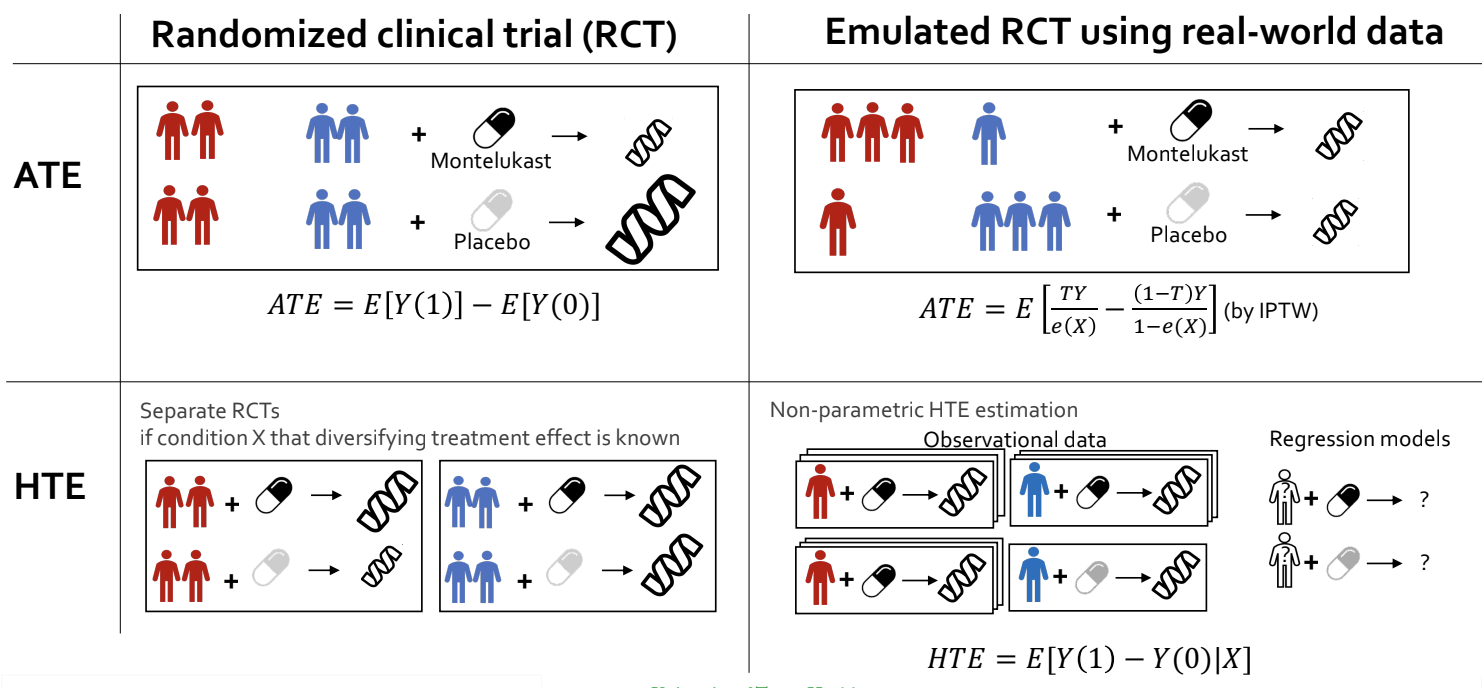
Average Treatment effect 측정
- 보통 ATE 활용 (\(ATE = E[Y(1) - Y(0)]\))
- 실 세계에서는 selection bias가 발생함

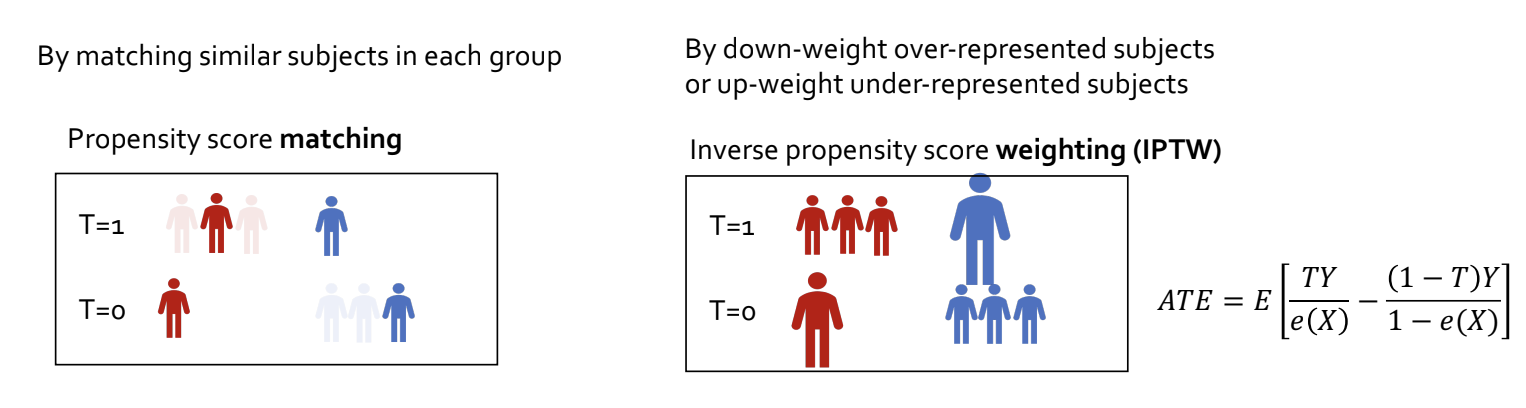
- Propensity score 방법 (matching vs weighting)
- matching: 비슷한 성향을 가진 유저끼리 clustering
- weighting: rare한 특성 데이터에 높은 가중치를 부여하고, 많은 특성의 데이터에 낮은 가중치를 부여
Heterogeneity Treatment effect (HTE)
- CATE(conditional average treatment effect), ITE(individual treatment effect)로도 불림
- 약물은 보통 5-60% 사람들만 혜택을 본다고 생각함
- 어떤 사람이 혜택을 받고 어떤 사람이 혜택을 받지 않는지 알면 도움이 될 것

Session 14-2
Heterogeneous treatment effect 측정 방법
- regression 모델로 특성의 뉘앙스, 문맥을 학습
- treatment effect(HTE)를 추정
- semi-parametric structural equation model
- imputing counterfactual outcome
- propensity score로 weighting을 할 것인지 선택
- method: double maching learning, meta learners, balanced representation learning

Double Machine Learning
- learning coefficient of semi-parametric structual equation model
- Output 예측 모델, Treatment 예측 모델 각각을 만들어서 estimate
- 장점:
- T(Treatment)가 structual equation에 들어있기 때문에 flexible 함
- confidence 구간을 구할 수 있음
- constraint를 없애면, \(\tau(X)\)만 infer 하는 R-learner로 쓸 수 있음

Meta Learners
- non-parametric HTE estimation by imputing missing counterfactual outcome
- 결측치 예측 → HTE 추정
- 실용적인 방법론
- 문제를 여러 가지로 분할함
- 뉘앙스 learn
- Outcome learn
- HTE 추정
- 종류
- S-learner (에스 러너) → treatment 처치 여부 구분 없이 parameter를 공유하여 예측
- T-learner (투 러너) → treatment 처치 여부를 나눈 후에 Y(1), Y(0) 예측 모델을 각각 만들어서 활용
- X-learner (엑스 러너) → T-learner에 몇 가지를 추가한 방식
- treatment 처치 여부에 따른 HTE 예측 모델을 추가적으로 만듦
- 데이터 imbalance를 해결하기 위한 목적
- 그 이후 weighted average를 함
- selection bias를 고려함 (S, T-learner는 고려 안 함)
- treatment 처치 여부에 따른 HTE 예측 모델을 추가적으로 만듦

Balanced representation learning
- covariate shift using neural network
- 3가지 loss가 존재
- selection bias를 줄이는 covariate shift
- outcome별 (\(Y(0), Y(1)\)) loss

- 어떤 모델을 써야 할까..? → evaluation 방법
- Empirical evaluation ⇒ 정확하지 않음
- IHDP: 사람이 manual 하게 계산하는 방법 → ground truth가 작음
- Synthetic data를 만들어서 테스트
- Theoretical evaluation ⇒ paper에 많이 등장
- tight error bound
- Empirical evaluation ⇒ 정확하지 않음
- IHDP 실험 결과

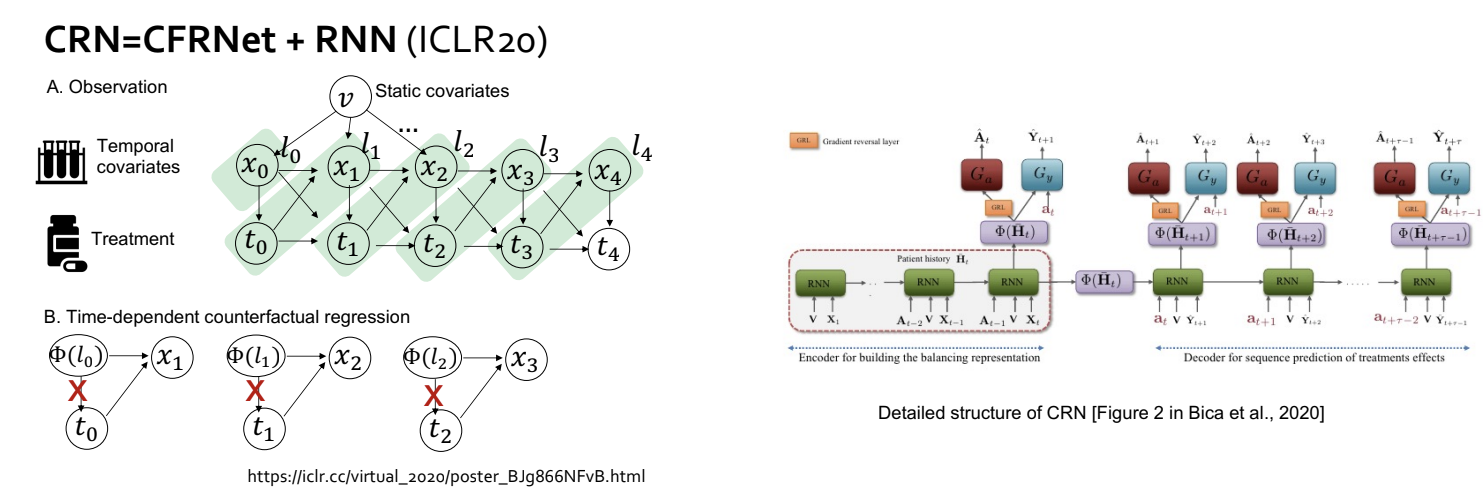
Time-dependent treatment로 HTE 추정 방법
- x: 시간에 따라 변하는 환자의 condition
- t: 시간에 따라 변하는 treatment
Summary
- ATE vs HTE
- 어떤 모델을 사용해야 하나?
- sparse vs unstructered?
- sparse → Meta learner
- unstructered → Balanced representation learning
- Static vs temporal
- large vs small
- small → Meta learner (Balanced representation learning는 overfitting 문제가 발생 가능)
- large → Balanced representation learning
- sparse vs unstructered?
- assumption이 지켜질 것인가?
- hidden confounders를 주의
- treatment assignment가 deterministic 한 것 또한 주의
- data quality
- treatment effect는 상대적인 것 (placebo를 정하는 것이 매우 어려움)
반응형
'Mathematics > Causal inference' 카테고리의 다른 글
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 16 (0) | 2023.10.11 |
|---|---|
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 15 (0) | 2023.10.03 |
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 13 (0) | 2023.09.27 |
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 11 (0) | 2023.09.05 |
| [KSSCI 2021] 인과추론의 데이터 과학 - Session 9 (0) | 2023.08.29 |




댓글